
Navigable
▒ 컬렉션 프레임웍 (Collections Framework)
- 컴렉션 프레임웍 : 데이터 군을 저장하는 클래스들을 표준화한 설계, 컬렉션을 쉽게 펼리하게 다룰 수 있는 다양한 클래스 제공
- 컬렉션 : 여러 객체(데이터)를 모아 놓은 것
- 프레임웍 (framework) : 표준화, 정형화된 체계적인 프로그래밍 방식
- 컬렉션 클래스 : 다수의 데이터를 저장할 수 있는 클래스(예 : Vector, ArrayList, HashSet)
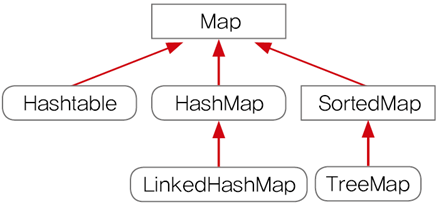
◎ 컬렉션 프레임웍의 핵심 인터페이스
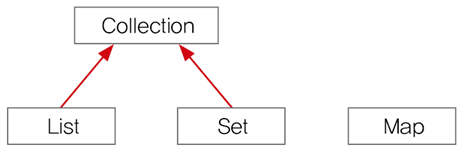
- 컬렉션 프레임 웍에서 컬렉션데이터 그룹을 크게 3가지 타입으로 나눌 수 있음
- List 인터페이스
- Set 인터페이스
- Map 인터페이스
- List 인터페이스와 Set인터페이스는 많은 공통 부분이 있어서 Collection 인터페이스로 묶어놓음
- 컬렉션 프레임윅의 모든 컬렉션 클래스들은 List, Set, Map 중 하나를 구현하고 있어야 함
- 구현한 인터페이스의 이름이 컬렉션 클래스의 이름에 포함되어있어서 이름만으로도 클래스의 특징을 쉽게 알 수 있음
- Vector나 Hashtable과 같은 기존의 컬렉션 클래스들은 가능한 지양할 것
■ Collection 인터페이스
| 반환타입 | 메서드 | 설명 |
| boolean | add(Object o) | 지정된 객체(o) 추가 |
| boolean | addAll(Collection c) | 합집합 객체 c 에 담긴 모든 요소 추가 |
| void | clear() | 모든 요소 삭제 |
| boolean | contains(Object o) | 부분집합 지정된 객체(o)가 포함되어있으면 true |
| boolean | containsAll(Collection c) | 객체 c에 담긴 모든 요소가 포함되어 있으면 true |
| boolean | equals(Object o) | 서로 같은지 비교. 같으면 true |
| int | hashCode() | hash code 반환 |
| boolean | isEmpty() | 비어있는지 확인. 비어있으면 true |
| Iterator | iterator() | iterator 객체로 반환 |
| boolean | remove(Object o) | 지정된 객체 삭제 |
| boolean | removeAll(Collection c) | 차집합 객체 c에 담긴 요소 중 일치하는 요소들 모두 삭제 |
| boolean | retainAll(Collection c) | 교집합 지정된 객체 c 의 요소와 일치하는 요소들만 남기고 다른 요소들은 전부 삭제. 이 과정에 요소 구성에 변화가 있으면 true, 변화가 없으면 false (c의 요소와 일치하는 요소가 있으면 true. 일치하는게 없으면 false) |
| int | size() | 저장된 객체 수 반환 |
| Object[] <T> T[] |
toArray() toArray(T[] a) |
저장된 객체를 객체배열( Object[] )로 반환 지정된 배열에 요소의 객체를 저장해서 반환 |
■ List 인터페이스
- 중복 허용
- 저장 순서 유지
- Vector 대신 ArrayList 쓸 것
- 차이점은 동기화 유무
- ArrayList는 동기화 x
- import java.util.List; 쓸 것
| 반환타입 | 메서드 | 설명 |
| void | add(Object o) add(int index, Object element) |
저장된 위치에 요소 추가 |
| boolean | addAll(int index, Collection c) | 지정된 위치에 요소 추가. 추가하면 true |
| E | get(int index) | 지정된 위치에 있는 요소값 반환 |
| int | indexOf(Object o) | 지정된 객체의 위치 반환 (순방향) |
| int | lastIndexOf(Object o) | 지정된 객체 위치 반환 (역방향) |
| ListIterator | listIterator() listIterator(int index) |
ListIterator 객체로 반환 |
| Object | remove(int index) | 지정된 위치의 요소 삭제하고 삭제된 요소 반환 |
| Object | set(int index, Object element) | 지정된 위치의 요소값 변경 |
| void | sort(Comparator c) | 지정된 비교자(comparator)로 리스트 정렬 |
| List | subList(int fromIndex, int toIndex) | 지정된 범위에 있는 객체 반환 |
■ Set 인터페이스
- 순서 x
- 중복 x
- Collection 인터페이스 메서드와 동일
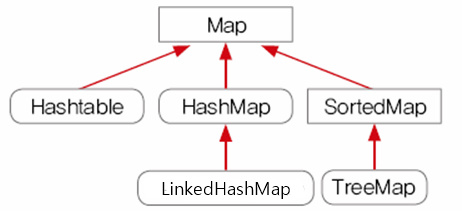
■ Map 인터페이스
- 키(key)와 값(value)을 하나의 쌍으로 묶어서 저장
- 키(key) 중복 불가능
- 값(value) 중복 가능
- 기존에 저장된 데이터와 중복된 키 값을 저장하면 기존의 키 값은 사라지고 마지막에 저장된 값만 남게됨
- Hashtable 대신 HashMap 쓸 것
- 차이점은 동기화 유무.
- HaspMap은 동기화 x
- LinkedHashMap 클래스는 순서 있음
| 제어자 반환타입 |
메서드 | 설명 |
| void | clear() | Map의 모든 객체 삭제 |
| boolean | containsKey(Object key) | 일치하는 key값이 있는지 확인 일치하면 true |
| boolean | containsValue(Obejct value) | 일치하는 value값 있는 지 확인 일치하면 true |
| Set | entrySet() | key-value쌍을 Map.Entry 타입의 객체로 저장한 Set 으로 반환 모든 key-value 값을 한 쌍으로 묶은 상태로 반환 |
| Set | keySet() | 모든 key 값 반환 |
| Collection | values() | 모든 value 값 반환 |
| boolean | equals(Object o) | 같은지 비교. 같으면 true |
| Object | get(Object key) | key값에 맞는 value값 반환 |
| int | hashCode() | 해시코드값 반환 |
| boolean | isEmpty() | 비어있는지 확인. 비어있으면 true |
| Object | put(Object key, Object value) | key-value 값 추가 |
| void | putAll(Map t) | t 객체에 저장되어 있는 모든 key-value 값 추가 (합집합) |
| Object | remove(Object key) | key값에 맞는 key-value 값 삭제 |
| int | size() | Map에 저장된 key-value 쌍의 개수 반환 |
□ Map.Entry 인터페이스
- Map.Entry 인터페이스는 Map 인터페이스의 내부 인터페이스(inner interface)
- Map에 저장되는 key-value쌍을 다루기 위해 내부적으로 Entry 인터페이스 정의
- Map 인터페이스를 구현할 때 Map.Entry 인터페이스도 함께 구현 해야함
- Map 메서드에서 entrySet()의 반환타입이 Set인데 이 때 Set에 저장된 각각의 요소들의 타입이 Map.Entry 타입임
| 반환타입 | 메서드 | 설명 |
| boolean | equals(Object o) | 동일한 Entry인지 비교. 같으면 true |
| Object | getKey() | key값 반환 |
| Object | getValue() | value값 반환 |
| int | hashCode() | 해시코드 반환 |
| Object | setValue(Object value) | value값 변경 |
◎ ArrayList 클래스
- 컬렉션 프레임웍에서 가장 많이 사용되는 컬렉션 클래스
- List 인터페이스 구현
- 저장순서 유지, 중복 허용
- Object[] 배열을 이용해서 데이터를 순차적으로 저장
- import java.util.ArrayList; 쓸 것
- 지정된 크기보다 더 많은 객체를 저장하면 자동적으로 크기가 늘어나긴 하지만 이 과정에서 처리시간이 많이 소요되므로 미리 여유롭게 설정할 것
■ ArrayList 클래스 생성자
| 반환타입 | 생성자 | 설명 |
| ArrayList | ArrayList() | 크기가 10인 ArrayList 인스턴스 생성 |
| ArrayList(Collection c) | c 요소를 포함하는 ArrayList 인스턴스 생성 | |
| ArrayList(int initialCapacity) | 지정된 크기를 갖는 ArrayList 인스턴스 생성 |
■ ArrayList 클래스 메서드
| 반환타입 | 메서드 | 설명 |
| boolean void |
add(Object o) add(int index Object element) |
마지막 순번에 요소 추가. 성공하면 true 지정된 위치에 요소 저장 |
| boolean | addAll(Collection c) allAll(int index, Collection c) |
c의 모든 요소 저장. 성공하면 true 지정된 위치에 c의 모든 요소 저장. 성공하면 true |
| void | clear() | 모든 요소 삭제 |
| Object | clone() | ArrayList 복사 |
| boolean | contains(Object o) | 객체 o 요소가 포함되는지 안되는지 확인. 포함하면 true |
| void | ensureCapacity(int minCapacity) | ArrayList의 최소 크기 설정 |
| Object | get(int index) | 지정된 위치의 값 반환 |
| int | indexOf(Object o) | 지정된 값이 저장돤 index값 반환 (순방향) |
| int | lastIndexOf(Object o) | 지정된 값이 저장된 index값 반환 (역방향) |
| boolean | isEmpty() | ArrayList가 비어있는지 확인. 비어있으면 true |
| Iterator | iterator() | ArrayList → Iterator 변환 |
| ListIterator | ListIterator() ListIterator(int index) |
ArrayList → ListIterator 변환 지정된 위치로부터 시작하는 ArrayList를 ListIterator로 변환 |
| Object boolean |
remove(int index) remove(Object o) |
지정된 위치의 값 제거 지정된 요소 제거. 성공하면 true |
| boolean | removeAll(Collection c) | c 의 요소와 중첩된 모든 요소 삭제. 성공하면 true |
| boolean | retainAll(Collection c) | c와 공통된 요소만 남기고 나머지 다 삭제. 성공하면 true |
| Object | set(int index, Object element) | 지정된 위치에 값 변경 |
| int | size() | 저장된 요소(객체) 개수 반환 |
| void | sort(Comparator c) | 지정된 정렬 기준으로 정렬 |
| List | subList(int fromIndex, int toIndex) | 주어진 범위에 저장된 값들을 List에 담아서 반환 |
| Object[] | toArray() toArray(Object[] a) |
저장된 모든 객체들을 객체배열로 반환 저장된 모든 객체들을 객체배열a에 담아서 반환 |
| void | trimToSize() | 용량을 크기에 맞게 줄임 (빈 공간 없앰) |
예제1
import java.util.ArrayList;
import java.util.Collections;
class prac{
public static void main (String[] args) {
ArrayList list1 = new ArrayList(10);
list1.add(new Integer(5));
list1.add(new Integer(4));
list1.add(new Integer(2));
list1.add(new Integer(0));
list1.add(new Integer(1));
list1.add(new Integer(3));
System.out.println(list1); // [5, 4, 2, 0, 1, 3]
ArrayList list2 = new ArrayList(list1.subList(1, 4));
System.out.println(list2); // [4, 2, 0]
// 정렬
Collections.sort(list1);
Collections.sort(list2);
System.out.println(list1); // [0, 1, 2, 3, 4, 5]
System.out.println(list2); // [0, 2, 4]
// list1에 list2가 포함되는지 안되는지 확인
System.out.println(list1.containsAll(list2)); // true
list2.add("B");
list2.add("C");
list2.add(3, "A");
System.out.println(list2); // [0, 2, 4, A, B, C]
list2.set(3, "AA");
System.out.println(list2); // [0, 2, 4, AA, B, C]
// list1 요소 중 list2의 공통요소만 남고 나머지 다 삭제
list1.retainAll(list2);
System.out.println(list1); // [0, 2, 4]
list2.removeAll(list1);
System.out.println(list2); // [AA, B, C]
}
}Collections 클래스를 이용해서 정렬
예제2
import java.util.ArrayList;
import java.util.List;
class prac{
public static void main (String[] args) {
final int LIMIT = 10;
String source = "0123456789abcdefghijABCDEFGHIJ!@#$%^&*()ZZZ";
int length = source.length(); // 43
List list = new ArrayList(length/LIMIT + 10); // 14
for(int i=0; i< length; i+=LIMIT) {
if (i+10 <length) {
list.add(source.substring(i, i+10));
} else {
list.add(source.substring(i));
}
}
for(int i=0; i<list.size(); i++) {
System.out.println(list.get(i));
}
}
}
/* 출력값
0123456789
abcdefghij
ABCDEFGHIJ
!@#$%^&*()
ZZZ
*/
예제3
import java.util.Vector;
class prac{
public static void main (String[] args) {
Vector v = new Vector(5);
v.add("1");
v.add("2");
v.add("3");
System.out.println(v);
print(v);
v.trimToSize();
System.out.println("== After trimToSize() ==");
print(v);
v.ensureCapacity(6);
System.out.println("== After ensureCapacity(6) ==");
print(v);
v.setSize(7);
System.out.println("== After setSize(7) ==");
print(v);
v.clear();
System.out.println("== After ensureCapacity(6) ==");
print(v);
}
static void print(Vector v) {
System.out.println(v);
System.out.println("size : " + v.size());
System.out.println("capacity : " + v.capacity());
System.out.println();
}
}
/* 출력값
[1, 2, 3]
[1, 2, 3]
size : 3
capacity : 5
== After trimToSize() ==
[1, 2, 3]
size : 3
capacity : 3
== After ensureCapacity(6) ==
[1, 2, 3]
size : 3
capacity : 6
== After setSize(7) ==
[1, 2, 3, null, null, null, null]
size : 7
capacity : 12
== After ensureCapacity(6) ==
[]
size : 0
capacity : 12
*/리스트 크기를 늘릴 때 기존 리스트에서 크기를 늘리는것이 아니라, 크기가 더 큰 리스트를 새로 만든 후, 기존 리스트를 복사해서 새로운 리스트를 반환하는 것. 그러기 때문에 실행중에 크기를 늘리는것은 효율이 떨어짐
◎ Linked List
- 불연속적으로 존재하는 데이터를 서로 연결(link)한 형태
- 배열의 단점인 크기를 변경할 수 없는것과 비순차적인 데이터의 추가, 삭제 시간이 오래 걸린다는것을 보안한 자료구조
- 링크드 리스트의 각 요소(node)들은 자신과 연결된 다음 요소의 참조(주소값)와 데이터로 구성되어 있음
- 링크드 리스트 요소(노드) = 다음 요소의 참조값 + 데이터
- 데이터 추가, 삭제 속도가 빠름
- List 인터페이스 구현
- import java.util.LinkedList; 쓸 것
■ 배열과 LinkedList의 차이


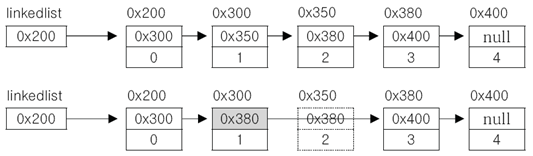
■ Linked List 데이터 삭제
- 단 한 번의 참조변경만으로 가능
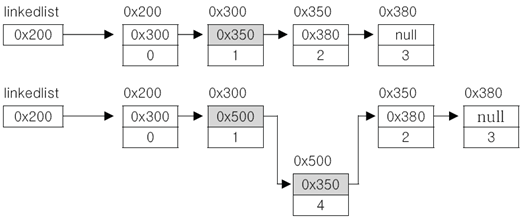
■ Linked List 데이터 추가
- 한 번의 Node 객체생성과 두 번의 참초변경만으로 가능
◎ Doubly Linked List ㅡ 이중 연결 리스트
- 링크드 리스트 (LinkedList)의 단점인 데이터 접근성이 나쁜것을 보안한 자료구조
- 링크드 리스트보다 각 요소에 대한 접근과 이동이 쉽기 때문에 링크드 리스트보다 더 많이 사용됨

◎ Doubly Circular Likned List ㅡ 이중 원형 연결 리스트
- 더블 링크드 리스트(이중 연결 리스트)의 첫번째 요소와 마지막 요소를 서로 연결시킨 것

■ LinkedList 생성자
| 생성자 | 설명 |
| LinkedList() | LinkedList 객체 생성 |
| LinkedList(Collection c) | 컬렉션 c를 포함한 LinkedList 객체 생성 |
■ LinkedList 메서드
| 반환타입 | 메서드 | 설명 |
| ① boolean ② void |
① add(Object o) ② add(int index, Object element) |
① 맨 앞에 값 추가. 성공하면 true. 저장공간 부족시 IllegalStateException 예외 발생 ② 지정된 위치에 객체 추가 저장공간 부족시 IllegalStateException 예외 발생 |
| boolean boolean |
addAll(Collection c) addAll(int index, Collection c) |
c에 포함된 모든 요소를 LinkedList의 끝에 추가. 성공하면 true (합집합) 지정된 위치에 c의 모든 요소 추가. 성공하면 true (합집합) |
| void | addFirst(Object o) | 맨 앞에 값 추가 |
| void | addLast(Object o) | 맨 뒤에 값 추가 |
| Object | offer(Object o) | 지정된 객체(o)를 LinkedList 의 끝에 추가. 성공하면 true 예외 발생시키지 않음 |
| boolean | offerFirst(Object o) | 맨 앞에 값 추가. 성공시 true |
| boolean | offerLast(Object o) | 맨 뒤에 값 추가. 성공시 true |
| void | push(Object o) | 맨 앞에 값 추가 addFirst()와 동일 |
| void | clear() | 모든 요소 삭제 |
| boolean | contains(Object o) | 지정된 객체를 포함하면 true |
| boolean | containsAll(Collection c) | 지정된 객체의 모든 요소를 포함하면 true |
| Object | get(int index) | 지정된 위치의 객체 반환 |
| Object | getFirst() | 첫 번째 요소 반환 |
| Object | getLast() | 마지막 요소 반환 |
| Object | element() | 첫 번째 요소값 반환 |
| Object | peek() | 첫 번째 요소값 반환 값 비어있으면 null 반환 예외 발생시키지 않음 |
| Object | peekFirst() | 첫 번째 요소 값 반환 |
| Object | peekLast() | 마지막 요소 값 반환 |
| int | indexOf(Object o) | 지정된 객체가 저장된 index값 반환 (순방향) |
| int | lastIndexOf(Object o) | 지정된 객체가 저장된 index값 반환 (역방향) |
| boolean | isEmpty() | 비어있으면 true |
| Iterator | iterator() | LinkedList → Iterator 변환 |
| Iterator | descendingIterator() | 역순으로 조회하기 위한 DescendingIterator 반환 |
| ListIterator | listIterator() listIterator(int index) |
LinkedList → ListIterator 변환 지정된 위치의 객체부터 값을 갖는 LinkedList를 Iterator로 변환 |
| ① Object ② boolean ③ Object |
① remove(int index) ② remove(Object o) ③ remove() |
① 지정된 위치의 객체 반환 후 제거 비어있으면 NoSuchElementException 예외 발생 ② 지정된 객체 제거 성공시 true 비어있으면 NoSuchElementException 예외 발생 ③ 첫 번째 요소 반환 후 제거 비어있으면 NoSuchElementException 예외 발생 |
| boolean | removeAll(Collection c) | 차집합 c의 요소 중 공통요소 모두 삭제. 성공시 true |
| Object | removeFirst() | 첫 번째 요소 반환 후 제거 비어있으면 NoSuchElementException 예외 발생 |
| Object | removeLast() | 마지막 번째 요소 반환 후 제거 비어있으면 NoSuchElementException 예외 발생 |
| boolean | removeFirstOccurrence(Object o) | 첫 번째로 일치하는 객체 제거. 성공시 true |
| boolean | removeLastOccurrence(Object o) | 마지막으로 일치하는 객체 제거. 성공시 true |
| Object | poll() | 첫번 째 요소 반환후 제거 비어있으면 null 반환 예외 발생 x |
| Object | pollFirst() | 첫 번째 요소 반환후 제거 |
| Object | pollLast() | 마지막 요소 반환 후 제거 |
| Object | pop() | 첫 번째 값 반환후 제거 removeFirst()와 동일 |
| boolean | retainAll(Collection c) | 교집합 c의 요소와 공통요소만 남기고 나머지 요소 삭제. 성공시 true |
| Object | set(int index, Object element) | index 값을 element 값으로 변경후 element값 반환 |
| int | size() | 저장된 객체 수 반환 |
| List | subList(int fromIndex, int toIndex) | LinkedList 일부를 List로 반환 |
| Object[] | toArray() toArray(Object[] a) |
LinkedList → Array 변환 저장된 모든 객체들을 객체배열a에 담아서 반환 |
◎ ArrayList와 LinkedList 성능 비교
- 데이터 개수가 변하지 않는 경우라면 ArrayList를 쓰고, 데이터 개수의 변경이 잦다면 LinkedList 쓸 것
- 데이터를 저장할 때는 ArrayList를 사용한 다음, 작업할 때는 LinkedList로 데이터를 옮겨서 작업하면 효율 좋음
- 순차적으로 데이터 추가/삭제 → ArrayList가 더 빠름
- 비순차적으로 데이터 추가/삭제 → LinkedList가 더 빠름
- 접근시간(access time) → ArrayList가 더 빠름
| 컬렉션 | 읽기(접근시간) | 추가/삭제 | 비교 |
| ArrayList | 빠름 | 느림 | 순차적인 추가삭제 빠름 비효율적인 메모리 사용 |
| LinkedList | 느림 | 빠름 | 데이터가 많을수록 접근성 떨어짐 |
예제1
import java.util.ArrayList;
import java.util.LinkedList;
import java.util.List;
public class prac {
public static void main (String[] args) {
ArrayList al = new ArrayList(2000000);
LinkedList ll = new LinkedList();
System.out.println("== 순차적으로 추가하기 ==");
System.out.println("ArrayList: " + add1(al));
System.out.println("LinkedList: "+ add1(ll));
System.out.println();
System.out.println("== 중간에 추가하기 ==");
System.out.println("ArrayList: " + add2(al));
System.out.println("LinkedList: "+ add2(ll));
System.out.println();
System.out.println("== 중간에 삭제하기 ==");
System.out.println("ArrayList: " + remove2(al));
System.out.println("LinkedList: "+ remove2(ll));
System.out.println();
System.out.println("== 순차적으로 삭제하기 ==");
System.out.println("ArrayList: " + remove1(al));
System.out.println("LinkedList: "+ remove1(ll));
}
static long add1(List list){
long start = System.currentTimeMillis();
for(int i=0; i<1000000; i++) {
list.add(i+"");
}
long end = System.currentTimeMillis();
return end - start;
}
static long add2(List list) {
long start = System.currentTimeMillis();
for(int i=0; i<10000; i++) {
list.add(500, "X");
}
long end = System.currentTimeMillis();
return end - start;
}
static long remove1(List list) {
long start = System.currentTimeMillis();
for(int i=list.size()-1; i>=0; i--) {
list.remove(i);
}
long end = System.currentTimeMillis();
return end - start;
}
static long remove2(List list) {
long start = System.currentTimeMillis();
for(int i=0; i<10000; i++) {
list.remove(i);
}
long end = System.currentTimeMillis();
return end - start;
}
}
/* 출력값
== 순차적으로 추가하기 ==
ArrayList: 285
LinkedList: 426
== 중간에 추가하기 ==
ArrayList: 3816
LinkedList: 11
== 중간에 삭제하기 ==
ArrayList: 3326
LinkedList: 107
== 순차적으로 삭제하기 ==
ArrayList: 8
LinkedList: 18
*/순차적으로 추가/삭제 → ArrayList가 LinkedList 보다 더 빠름
중간 추가/삭제 → LinkedList가 ArrayList보다 더 빠름
예제2
import java.util.ArrayList;
import java.util.LinkedList;
import java.util.List;
public class prac {
public static void main (String[] args) {
ArrayList al = new ArrayList(1000000);
LinkedList ll = new LinkedList();
add(al);
add(ll);
System.out.println("== 접근시간 테스트 ==");
System.out.println("ArrayList: " + access(al));
System.out.println("LinkedList: " + access(ll));
}
static void add(List list) {
for(int i=0; i<100000; i++) list.add(i + "");
}
static long access(List list) {
long start = System.currentTimeMillis();
for(int i=0; i<10000; i++) {
list.get(i);
}
long end = System.currentTimeMillis();
return end - start;
}
}
/* 출력값
== 접근시간 테스트 ==
ArrayList: 1
LinkedList: 149
*/접근시간 → ArrayList가 LinkedList보다 더 빠름
■ 배열 주소 계산하기


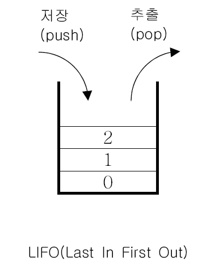
◎ Stack (스택) 클래스
- LIFO(Last In First Out) 구조 : 마지막에 저장된 것을 제일 먼저 꺼냄
- 활용 예시 : 수식계산, 수식괄호 검사, 워드프로세서의 undo/redo, 웹 브라우저의 뒤로/앞으로 기능
- Vector 클래스를 상속받음
- import java.util.Stack; 쓸 것
| 반환타입 | 메서드 | 설명 |
| boolean | empty() | 비어있는지 알려줌. 비어있으면 true |
| Object | peek() | Stack의 맨위에 저장된 객체 반환 비었을 때 EmptyStackException 발생 |
| Object | pop() | Stack의 맨위에 저장된 객체 반환 후 삭제 비었을 때 EmptyStackException 발생 |
| Object | push(Object item) | 객체(item) 저장 |
| int | search(Object o) | 객체(o)가 있는 위치(index)값 반환. 없으면 -1 반환 배열과 달리 위치는 0이 아닌 1부터 시작 |
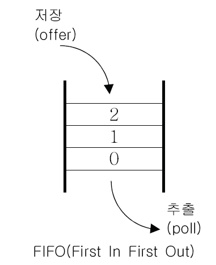
◎ Queue (큐) 인터페이스
- FIFO(First In First Out) 구조 : 제일 먼저 저장한 것을 제일 먼저 꺼냄
- 활용 용도 : 최근 사용 문서, 인쇄작업 대기목록, 버퍼(buffer)
- LinkedList 클래스를 통해 기능 구현
- Queue 인터페이스를 구현한 클래스
- import java.util.Queue; 쓸 것
| 반환타입 | 메서드 | 설명 |
| boolean | add(Object o) | 객체(o) 추가. 성공하면 true 반환 저장공간 부족시 IllegalStateException 예외 발생 |
| Object | remove() | 맨 아래에 있는 객체 반환후 제거 비어있으면 NoSuchElementException 예외 발생 |
| Object | element() | 맨 아래에 있는 객체 반환 비어있으면 NoSuchElementException 예외 발생 |
| boolean | offer(Object o) | 객체(o) 저장. 성공하면 true 예외 발생 x |
| Object | poll() | 맨 아래에 있는 객체 반환후 제거 비어있으면 null 반환 예외발생 x |
| Object | peek) | 맨 아래에 있는 객체 반환 비어있으면 null 반환 예외발생 x |
- offer(), poll(), peek() 메서드를 주로 사용할 것 → 예외를 발생시키지 않기 때문
예제1
import java.util.LinkedList;
import java.util.Queue;
import java.util.Stack;
public class prac {
public static void main (String[] args) {
Stack st = new Stack();
Queue q = new LinkedList();
st.push("0");
st.push("1");
st.push("2");
q.offer("0");
q.offer("1");
q.offer("2");
System.out.println("== Stack == ");
while(!st.empty()) {
System.out.println(st.pop());
}
System.out.println("== Queue ==");
while(!q.isEmpty()) {
System.out.println(q.poll());
}
}
}
/* 출력값
== Stack ==
2
1
0
== Queue ==
0
1
2
*/Stack과 Queue의 값 반환 순서 차이를 자세히 볼 것
예제2
import java.util.Stack;
public class prac {
static Stack back = new Stack();
static Stack forward = new Stack();
public static void main (String[] args) {
goURL("1. 네이트");
goURL("2. 야후");
goURL("3. 네이버");
goURL("4. 다음");
printStatus();
goBack();
System.out.println("== 뒤로가기 버튼 누른 후 ==");
printStatus();
goBack();
System.out.println("== 뒤로가기 버튼 누른 후 ==");
printStatus();
goForward();
System.out.println("== 앞으로 버튼 누른 후 ==");
printStatus();
goURL("유튜브");
System.out.println("새로운 주소창 이동");
printStatus();
}
static void goURL(String url) {
back.push(url);
if(!forward.empty()) {
forward.clear();
}
}
static void goBack() {
if(!back.empty()) {
forward.push((back.pop()));
}
}
static void goForward() {
if(!forward.empty()) {
back.push(forward.pop());
}
}
static void printStatus() {
System.out.println("back : " + back);
System.out.println("forward : " + forward);
System.out.println("현재 화면 : " + back.peek());
System.out.println();
}
}
/* 출력값
back : [1. 네이트, 2. 야후, 3. 네이버, 4. 다음]
forward : []
현재 화면 : 4. 다음
== 뒤로가기 버튼 누른 후 ==
back : [1. 네이트, 2. 야후, 3. 네이버]
forward : [4. 다음]
현재 화면 : 3. 네이버
== 뒤로가기 버튼 누른 후 ==
back : [1. 네이트, 2. 야후]
forward : [4. 다음, 3. 네이버]
현재 화면 : 2. 야후
== 앞으로 버튼 누른 후 ==
back : [1. 네이트, 2. 야후, 3. 네이버]
forward : [4. 다음]
현재 화면 : 3. 네이버
새로운 주소창 이동
back : [1. 네이트, 2. 야후, 3. 네이버, 유튜브]
forward : []
현재 화면 : 유튜브
*/웹 브라우저의 '뒤로', '앞으로' 버튼 기능 구현
예제3
import java.util.EmptyStackException;
import java.util.Stack;
public class prac {
public static void main (String[] args) {
String str = "(2+3)*4";
System.out.println(str);
try {
Stack st = new Stack();
for(int i=0; i<str.length(); i++) {
char ch = str.charAt(i);
if(ch=='(') {
st.push(ch);
} else if (ch ==')') {
st.pop();
}
} // end of for
if(st.isEmpty()) {
System.out.println("괄호 개수 일치");
} else {
System.out.println("괄호 개수 불일치");
}
} catch(EmptyStackException e) {
System.out.println("괄호 개수 불일치");
}
}
}
/* 출력값
(2+3)*4
괄호 개수 일치
*/입력한 수식의 괄호 개수를 체크
예제4
import java.util.LinkedList;
import java.util.ListIterator;
import java.util.Queue;
import java.util.Scanner;
public class prac {
static Queue q = new LinkedList();
static final int MAX_SIZE =5;
public static void main (String[] args) {
while(true) {
System.out.print(">>");
try {
Scanner s = new Scanner(System.in);
String input = s.nextLine().trim();
if("".equals(input)) continue;
if(input.equalsIgnoreCase("q")){
System.exit(0);
} else if (input.equalsIgnoreCase("help")){
System.out.println(" help - 도움말을 보여줍니다 ");
System.out.println(" q 또는 Q - 프로그램 종료 ");
System.out.println(" history - 최근에 입력한 명령어를 " +MAX_SIZE+ "개");
} else if(input.equalsIgnoreCase("history")) {
int i=0;
save(input);
LinkedList tmp = (LinkedList)q;
ListIterator it = tmp.listIterator();
while(it.hasNext()) {
System.out.println(++i + "." + it.next());
}
} else {
save(input);
System.out.println(input);
}
} catch (Exception e) {
System.out.println("입력 오류");
}
}
}
static void save(String input){
if(!"".equals(input)) {
q.offer(input);
}
if(q.size() > MAX_SIZE) {
q.remove();
}
}
}Queue를 이용해서 유닉스의 history 명령어 구현
■ PriorityQueue
- Queue 인터페이스의 구현 클래스 중 하나
- 저장한 순서에 관계없이 우선순위(priority)가 높은 것 부터 꺼냄
- null 저장 불가능. null 저장시 NullPointerException 예외 발생
- 저장공간으로 배열을 사용하며, 각 요소를 힙(heap)이라는 자료구조 형태로 저장
- 자료 구조 힙(heap) 과 JVM 힙(heap)은 서로 이름만 같을뿐 다름
예제
import java.util.PriorityQueue;
import java.util.Queue;
public class prac {
public static void main (String[] args) {
Queue pq = new PriorityQueue();
pq.offer(3);
pq.offer(1);
pq.offer(5);
pq.offer(2);
pq.offer(4);
System.out.println(pq);
Object obj = null;
while((obj = pq.poll())!= null) {
System.out.println(obj);
}
}
}
/*
[1, 2, 5, 3, 4]
1
2
3
4
5
*/저장순서가 3,1,5,2,4인데 출력결과는 1,2,3,4,5
저장순서와 관계없이 우선순위가 높은것부터 값 반환
int형으로 저장해도 알아서 Integer로 오토박싱 해줌
Integer와 같은 Number 클래스의 자손들은 자체적으로 숫자를 비교하는 방법을 정의하고 있기 때문에 비교방법을 지정해주지 않아도 알아서 우선순위가 정해져있음
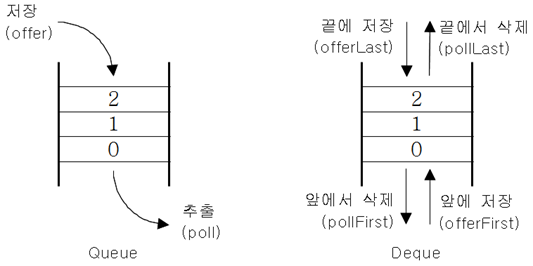
■ Deque (Double - Ended Queue)
- Queue의 변형인 인터페이스
- Deque의 조상은 Queue, 구현체는 ArrayDeque클래스와 LinkedList 클래스
- Queue와 달리 Deque(덱, 또는 디큐)은 양쪽 끝에 추가/삭제 가능
- Stack과 Queue 기능 둘 다 보유
| 설명 | Deque | Queue | Stack |
| 추가 | boolean OfferLast(Obejct o) | boolean offer(Object o) | boolean push(Object o) |
| 마지막 요소 반환 후 제거 | Object pollLast() | ㅡ | Object pop() |
| 첫 번째 요소 반환 후 제거 | Object pollFirst() | Obejct poll() | ㅡ |
| 첫 번째 요소 반환 | Object peekFirst() | Object peek() | ㅡ |
| 마지막 요소 반환 | Object peekLast() | ㅡ | Object peek() |
- 덱은 Queue와 Stack 기능을 둘 다 구현 가능
◎ Enumeration, Iterator, ListIterator 인터페이스
- 컬렉션에 저장된 데이터를 접근하는데 사용되는 인터페이스
- Enumeration은 Iterator 의 구버전
- ListIterator는 Iterator의 저븐성을 향상시킨 것 (단방향 → 양방향)
선택적 기능이라고 표시된 메서드는 기능을 반드시 구현하지 않아도 됨. 그러나 메서드의 몸통(body)는 반드시 만들어야함
public void remove(){
throw new UnsupportedOperationException();
}
위 코드처럼 기능구현 없이 몸통부분을 UnsupportedOperationException 예외처리로 할 것
단순히 public void remove(){}; 와 같이 구현하는것보다 예외로 던져서 구현하지 않는 기능이라는것을 표시할 것
위 코드에서 remove()메서드의 선언 부에 예외처리를 하지 않는 이유는 UnsupportedOperationException 예외가 RunTimeException 자손이기 때문
◎ Enumeration 인터페이스
- Iterator 인터페이스의 구버전
- 컬렉션 프레임웍이 만들어지기 이전에 사용된 것
- Enumeration 보단 Iterator를 사용할 것
- Iterator와 기능은 같음
■ Enumeration 인터페이스 메서드
| 반환타입 | 메서드 | 설명 |
| boolean | hasMoreElements() | 읽어올 요소 있는지 확인. 있으면 true |
| Object | nextElement() | 다음 요소를 읽어옴 nextElement()를 호출하기전에 hasMoreElements()를 먼저 호출해서 읽어올 요소가 남아있는지 확인하는것이 안전 |
◎ Iterator 인터페이스
- 컬렉션에 저장된 요소들을 읽어오는 방법을 표준화한 것
- 컬렉션에 iterator() 메서드를 호출해서 Iterator를 구현한 객체를 얻은 다음 반복문, 주로 while문을 사용해서 컬렉션 클래스의 요소들을 읽을 수 있음
Collection c = new ArrayList();
Iterator it = c.iterator();
while(it.hasNext()){ System.out.println(it.next()); }
- iterator() 메서드는 Collection 인터페이스에 정의된 메서드
- Map 인터페이스를 구현한 컬렉션 클래스는 키(key)와 값(value)을 쌍(pair)으로 저장하고 있기 때문에 iterator()를 직접 호출할 수 없고, 그 대신 keySet(), entrySet(), values()와 같은 메서드를 통해서 키와 값을 각각 따로 Set 의 형타나 Collection 형태로 얻어 온 후에 다시 iterator() 메서드를 호출해서 Iterator 인스턴스를 얻을 수 잇음
Map map = new HashMap();
Iterator it = map.entrySet().iterator();
- import java.util.Iterator; 쓸 것
- 재사용 안됨. 한 번 읽어온 요소를 또 다시 읽어오려면 또 다시 새로운 인스턴스 생성 해야함
■ Iterator 인터페이스 메서드
| 제어자 반환타입 |
메서드 | 설명 |
| boolean | hasNext() | 읽어 올 요소가 남아있는지 확인. 남아있으면 ture |
| Object | next() | 다음 요소 읽어옴 next()를 호출하기전에 hasNext()를 호출해서 읽어올 요소가 있는지 먼저 확인하는 것이 안전 |
| defalut void |
remove() | next()로 읽어 온 요소를 삭제. next()를 호출한 다음에 remove()를 호출해야함 (선택적 기능) |
| defalut void |
forEachRemaining(Consumer<? super E> action) | 컬렉션에 남아있는 요소들에 대해 지정된 작업(action)을 수행 람다식을 사용하는 디폴트 메서드 |
예제
import java.util.ArrayList;
import java.util.Iterator;
public class prac {
public static void main (String[] args) {
ArrayList list = new ArrayList();
list.add("1");
list.add("2");
list.add("3");
list.add("4");
list.add("5");
Iterator it = list.iterator();
while(it.hasNext()) {
Object obj = it.next();
System.out.println(obj);
}
}
}
/* 출력값
1
2
3
4
5
*/
◎ ListIterator 인터페이스
- Iterator 인터페이스를 상속 받아서 기능을 추가한 인터페이스
- 양방향으로 이동이 가능해서 Iterator보다 접근성이 뛰어남
- ArrayList클래스나 LinkedList클래스와 같이 List 인터페이스를 구현한 컬렉션에만 사용 가능
■ ListIterator 인터페이스 메서드
| 반환타입 | 메서드 | 설명 |
| void | add(Object o) | 요소 추가 (선택적 기능) |
| boolean | hasNext() | 읽어 올 다음 요소가 있는지 확인. 있으면 true |
| boolean | hasPrevious() | 읽어 올 이전 요소가 있는지 확인. 있으면 true |
| Object | next() | 다음 요소를 읽어옴 next()를 호출하기 전에 hasNext()를 먼저 호출해서 읽어 올 요소가 있는지 확인하는것이 안전 |
| Obejct | previous() | 이전 요소를 읽어옴 previous()를 호출하기 전에 hasPrevious()를 먼저 호출해서 읽어 올 요소가 있는지 확인하는것이 안전 |
| int | nextIndex() | 다음 요소의 index 값 반환 |
| int | previousIndex() | 이전 요소의 index 값 반환 |
| void | remove() | next() 또는 previous()로 읽어 온 요소 삭제 next()나 previous()를 먼저 호출한 후 remove()를 호출 할 것 (선택적 기능) |
| void | set(Object o) | next() 또는 previous()로 읽어 온 요소 값 변경 next()나 previous()를 먼저 호출한 후 set(Object o)를 호출 할 것 (선택적 기능) |
예제1
import java.util.ArrayList;
import java.util.ListIterator;
public class prac {
public static void main (String[] args) {
ArrayList list = new ArrayList();
list.add("1");
list.add("2");
list.add("3");
list.add("4");
list.add("5");
ListIterator it = list.listIterator();
while(it.hasNext()) System.out.print(it.next());
System.out.println();
while(it.hasPrevious()) System.out.print(it.previous());
System.out.println();
}
}
/* 출력값
12345
54321
*/
예제2
import java.util.ArrayList;
import java.util.Iterator;
public class prac {
public static void main (String[] args) {
ArrayList original = new ArrayList(10);
ArrayList copy1 = new ArrayList(10);
ArrayList copy2 = new ArrayList(10);
for(int i=0; i< 10; i++) {
original.add(i +"");
}
Iterator it = original.iterator();
while(it.hasNext()) {
copy1.add(it.next());
}
System.out.println("== Original → copy1로 복사 ==");
System.out.println("original: "+ original);
System.out.println("copy1: " + copy1);
System.out.println();
it = original.iterator(); // Iterator는 재사용이 안되므로, 다시 생성해서 얻어와야함
while(it.hasNext()) {
copy2.add(it.next());
it.remove();
}
System.out.println("== Original → copy2로 복사 ==");
System.out.println("original: "+ original);
System.out.println("copy2: " + copy1);
}
}
/* 출력값
== Original → copy1로 복사 ==
original: [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
copy1: [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
== Original → copy2로 복사 ==
original: []
copy2: [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
*/
◎ Arrays 클래스
- 배열을 다루는데 유용한 클래스
- Arrays 클래스에 정의된 메서드는 모두 static 메서드
- import java.util.Arrays; 쓸 것
■ 배열 출력 ㅡ toString()

- 일차원 배열에만 사용할 수 있음
■ 배열 복사 ㅡ copyOf(), copyOfRange()

■ 배열 채우기 ㅡ fill(), setAll()

- setAll() 메서드는 배열을 채우는데 사용할 함수형 인터페이스를 매개변수로 받음. 이 메서드를 호출할 때는 함수형 인터페이스를 구현한 객체를 매개변수로 지정하던가 아니면 람다식을 지정할 것
■ 배열의 정렬과 검색 ㅡ sort(), binarySearch()

- binarySearch()는 배열에서 지정된 값이 지정된 위치(index)를 찾아서 반환하는데, 반드시 배열이 정렬된 상태이어야 함. 그리고 만일 검색한 값과 일치하는 요소들이 여러 개 있다면, 이 중에서 어떤 것의 위치가 반환될지 알 수 없음
- 이진검색(binary search)를 사용하면 검색속도가 매우 빠름. 큰 배열의 검색에 유리. 단, 배열이 정렬이 되어있을 경우에만 사용할 수 있다는게 단점
■ 배열의 비교와 출력 ㅡ deepEquals(), deepToString(), equals()


- 다차원 배열 출력시 deepToString() 쓸 것
- equals()는 일차원 배열에만 사용 가능
- 다차원 배열 비교시 deepEquals() 쓸 것
■ 배열을 List로 변환 ㅡ asList(Object... a)


- 배열을 List에 담아서 반환
- 매개변수의 타입이 가변인수라서 배열 생성없이 저장할 요소들만 나열 가능
- asList()로 반환된 List의 크기는 변경 불가능 → 요소 추가, 삭제 불가능하지만 저장된 요소 값은 변경 가능
List list = new ArrayList(Arrays.asList(1,2,3,4,5));위 코드처럼 Arrays.asList(1,2,3,4,5) 를 ArraysList 생성자의 매개변수로 넣어줘서 새로운 ArrayList 생성하면 크기를 변경할 수 있는 List를 얻을 수 있음
예제
import java.util.Arrays;
public class prac {
public static void main (String[] args) {
int[] arr = {0, 1, 2, 3, 4};
int[][] arr2D = {{11, 12, 13}, {21, 22, 23}};
System.out.println("arr = " + Arrays.toString(arr)); // [0,1,2,3,4]
System.out.println("arr2D = " + Arrays.deepToString(arr2D)); // [[11,12,13], [21,22,23]]
int[] arr2 = Arrays.copyOf(arr, arr.length);
int[] arr3 = Arrays.copyOf(arr, 3);
int[] arr4 = Arrays.copyOf(arr, 7);
int[] arr5 = Arrays.copyOfRange(arr, 2, 4);
int[] arr6 = Arrays.copyOfRange(arr, 0, 7);
System.out.println("arr2 = " + Arrays.toString(arr2)); // [0,1,2,3,4]
System.out.println("arr3 = " + Arrays.toString(arr3)); // [0,1,2]
System.out.println("arr4 = " + Arrays.toString(arr4)); // [0,1,2,3,4,0,0]
System.out.println("arr5 = " + Arrays.toString(arr5)); // [2,3]
System.out.println("arr6 = " + Arrays.toString(arr6)); // [0,1,2,3,4,0,0]
int[] arr7 = new int[5];
Arrays.fill(arr7, 9);
System.out.println("arr7 = " + Arrays.toString(arr7)); // [9,9,9,9,9]
Arrays.setAll(arr7, i -> (int)(Math.random()*6)+1);
System.out.println("arr7 = " + Arrays.toString(arr7)); // [랜덤]
for(int i : arr7) {
char[] graph = new char[i];
Arrays.fill(graph, '*');
System.out.println(new String(graph) + i);
}
String[][] str2D = new String[][] {{"aaa","bbb"}, {"AAA", "BBB"}};
String[][] str2D2 = new String[][] {{"aaa","bbb"}, {"AAA", "BBB"}};
System.out.println(Arrays.equals(str2D, str2D2)); // false
System.out.println(Arrays.deepEquals(str2D, str2D2)); // true
char[] chArr = {'A', 'D', 'C', 'B', 'E'};
System.out.println("chArr = " + Arrays.toString(chArr)); // [A, D, C, B, E]
System.out.println("index of B = " + Arrays.binarySearch(chArr, 'B')); // -2 ← 정렬되지 않아서 잘못된 결과
Arrays.sort(chArr);
System.out.println("chArr = " + Arrays.toString(chArr)); // [A, B, C, D, E]
System.out.println("index of B = " + Arrays.binarySearch(chArr, 'B')); // 1
}
}
/* 출력값
arr = [0, 1, 2, 3, 4]
arr2D = [[11, 12, 13], [21, 22, 23]]
arr2 = [0, 1, 2, 3, 4]
arr3 = [0, 1, 2]
arr4 = [0, 1, 2, 3, 4, 0, 0]
arr5 = [2, 3]
arr6 = [0, 1, 2, 3, 4, 0, 0]
arr7 = [9, 9, 9, 9, 9]
arr7 = [3, 2, 4, 1, 5]
***3
**2
****4
*1
*****5
false
true
chArr = [A, D, C, B, E]
index of B = -2
chArr = [A, B, C, D, E]
index of B = 1
*/
◎ Comparator 인터페이스
- 객체를 정렬하는데 필요한 메서드를 정의한 인터페이스 (정렬 기준 제공)
- 기본 정렬기준 외에 다른 기준으로 정렬하고자 할 때 사용
- java.util 패키지 소속
- int compare(Object o1, Object o2) 메서드 구현할 것
- 두 객체가 같으면 0 반환
- o1 객체가 o2보다 크면 양수 반환
- o1 객체가 o2보다 작으면 음수 반환
- compare() 메서드 몸통 구현시 매개변수 타입이 Object이므로 매개변수를 Comparable 타입으로 형변환 할 것
◎ Comparable 인터페이스
- 객체를 정렬하는데 필요한 메서드를 정의한 인터페이스 (정렬 기준 제공)
- 기본 정렬기준을 구현하는데 사용
- Comparable 인터페이스를 구현하고 있는 클래스들은 같은 타입의 인스턴스끼리 서로 비교할 수 있는 클래스들
- 주로 Integer와 같은 wrapper 클래스와 String, Date, File과 같은 것들이며 기본적으로 오름차순, 즉 작은 값에서부터 큰 값의 순으로 정렬되도록 구현
- java.lang 패키지 소속
- int compareTo(Object o1) 메서드 정의되어 있음
- 두 객체가 같으면 0, 비교하는 값보다 작으면 음수, 크면 양수 반환
예제
import java.util.Arrays;
import java.util.Comparator;
public class prac {
public static void main (String[] args) {
String[] strArr = {"cat", "Dog", "lion", "tiger"};
Arrays.sort(strArr);
System.out.println(Arrays.toString(strArr)); // [Dog, cat, lion, tiger]
System.out.println();
Arrays.sort(strArr, String.CASE_INSENSITIVE_ORDER); // 대소문자 구분없이 기본정렬
System.out.println(Arrays.toString(strArr)); // [cat, Dog, lion, tiger]
System.out.println();
Arrays.sort(strArr, new Descending()); // 역순정렬
System.out.println(Arrays.toString(strArr)); // [tiger, lion, cat, Dog]
}
}
class Descending implements Comparator {
public int compare(Object o1, Object o2) {
if(o1 instanceof Comparable || o2 instanceof Comparable ) {
Comparable c1 = (Comparable)o1;
Comparable c2 = (Comparable)o2;
return c2.compareTo(c1); // 역순으로 변경
}
return -1;
}
}Arrays.sort() 메서드를 통해서 배열을 정렬할 때 Comparator 를 지정해주지 않으면 객체(주로 Comparable을 구현한 클래스의 객체)에 따라 달라짐
String 클래스의 Comparable 구현은 문자열이 사전 순으로 정렬되도록 작성되어 있음.
문자열의 오름차순 정렬은 공백, 숫자, 대문자, 소문자의 순으로 정렬되는것을 의미. 정확히는 문자의 유니코드의 순서가 작은 값에서 큰 값으로 정렬 된느 것
◎ HashSet 클래스
- Set 인터페이스를 구현한 가장 대표적인 컬렉션
- Set 인터페이스 특징대로 중복x, 순서x
- 중복없이 순서만 유지하려면 LinkedHashSet 클래스 사용할 것
- HashSet 클래스는 내부적으로 HashMap 클래스를 이용해서 만듦
■ HashSet 클래스 생성자
| 생성자 | 설명 |
| HashSet() | HashSet 객체 생성 |
| HashSet(Collection c) | 컬랙션 c를 포함하는 HashSet 객체 생성 |
| HashSet(int initialCapacity) | 주어진 값을 초기용량으로 하는 HashSet 객체 생성 |
| HashSet(int initialCapacity, float loadFactor) | 초기용량과 load factor를 지정한 HashSet 객체 생성 load factor은 컬렉션 클래스에 저장공간이 가득 차기 전에 미리 용량을 확보하기 위한 것 ex) load factor 값이 '0.8' 일 경우, 저장공간의 80%가 채워졌을 때 용량이 2배로 늘린다는것을 의미. 기본값은 0.75. 즉 75% |
■ HashSet 클래스 메서드
| 반환타입 | 메서드 | 설명 |
| boolean | add(Object o) | 객체(o) 저장 |
| boolean | addAll(Collection c) | 주어진 컬렉션(c)의 모든 객체 저장 합집합 |
| void | clear() | 저장된 모든 객체 삭제 |
| Object | clone() | HashSet 복제후 반환 얕은 복사 |
| boolean | contains(Object o) | 지정된 객체 포함하고 있는지 확인. 포함하면 true |
| boolean | containsAll(Collection c) | 컬렉션(c)의 모든 객체를 포함하고 있는지 확인 포함하면 true |
| boolean | isEmpty() | HashSet이 비어있는지 확인. 비어있으면 true |
| Iterator | iterator() | HashSet → Iterator 변환 후 반환 |
| boolean | remove(Object o) | 객체(o) 삭제. 성공하면 true |
| boolean | removeAll(Collection c) | 컬렉션(c)의 요소 중 공통요소 모두 제거. 성공하면 true |
| boolean | retainAll(Collection c) | 컬렉션(c)에 저장된 객체와 동일한것만 남기고 나머지 삭제 교집합 |
| int | size() | 저장된 객체 개수 반환 |
| Object[] | toArray() toArray(Object[] a) |
HashSet → Array 변환 후 반환 HashSet에 저장된 객체들을 객체배열(a) 에 담아서 반환 |
예제1
import java.util.HashSet;
import java.util.Set;
public class prac {
public static void main (String[] args) {
Object[] objArr = {"1", new Integer(1), "2", "2", "3", "3", "4", "4", "4"};
Set set = new HashSet();
for(int i=0; i<objArr.length; i++) set.add(objArr[i]);
System.out.println(set); // [1, 1, 2, 3, 4]
}
}set 출력시 '1' 이 두번 출력되는데 하나는 String인스턴스이고 다른 하나는 Integer인스턴스로 서로 다른 객체이며 중복으로 간주되지 않으나 어느게 어느것인지 구별은 못함
예제2
import java.util.Collections;
import java.util.HashSet;
import java.util.LinkedList;
import java.util.List;
import java.util.Set;
public class prac {
public static void main (String[] args) {
Set set = new HashSet();
for(int i=0; set.size()<6;i++) {
int num = (int)(Math.random()*45) + 1; // 1~45 랜덤 수
set.add(new Integer(num));
}
List list = new LinkedList(set);
Collections.sort(list);
System.out.println(list); // [8, 13, 19, 25, 26, 45]
}
}중복값 허용 안되는 HashSet의 성질을 이용한 로또번호 만들기 예제
예제3
import java.util.Iterator;
import java.util.LinkedHashSet;
import java.util.Set;
public class prac {
public static void main (String[] args) {
Set set = new LinkedHashSet();
int[][] board = new int[5][5];
for(int i=0; set.size()<25; i++) {
set.add((int)(Math.random()* 50) +1 + "");
}
Iterator it = set.iterator();
while(it.hasNext()) {
for(int i=0; i<5; i++) {
for(int j=0; j<5; j++) {
board[i][j] = Integer.parseInt(((String)it.next()));
System.out.print((board[i][j] >10? " " : " ") + board[i][j]);
}
System.out.println();
}
} /// end of while
}
}
/* 출력값
49 33 6 16 19
47 7 14 41 4
3 38 22 35 1
10 46 43 50 18
12 37 21 40 13
*/1~50 사이의 숫자 중에서 25개를 골라서 '5x5' 빙고판 제작
Iterator 클래스의 next() 메서드의 반환타입은 Object이므로 String 타입으로 형변환 함
HashSet 클래스 대신 LinkedHashSet 클래스를 이용한 이유는 HashSet은 저장 순서를 보장하지 않지만 자체적인 저장방식에 따라 순서가 결정되기 때문에 빙고판에 비슷한 크기의 숫자들이 몰려있을 수 있기에 LinkedHashSet 클래스를 사용함
예제4
import java.util.HashSet;
public class prac {
public static void main (String[] args) {
HashSet set = new HashSet();
set.add("abc");
set.add("abc");
set.add(new Person("David", 10));
set.add(new Person("David", 10));
System.out.println(set); // [abc, David : 10, David : 10]
}
}
class Person{
String name;
int age;
Person(String name, int age){
this.name = name;
this.age = age;
}
public String toString() {
return name + " : " + age;
}
}Person 클래스는 name과 age를 멤버변수로 갖음. 이름(name)과 나이(age)가 같으면 같은 사람으로 인식하도록 하려는 의도로 작성하였으나 실행 결과를 보면 나이와 이름이 같아도 다른 사람으로 인식해 두 번 출력됨
이것을 해결한 코드는 예제5번 코드
예제5
import java.util.HashSet;
import java.util.Objects;
public class prac {
public static void main (String[] args) {
HashSet set = new HashSet();
set.add("abc");
set.add("abc");
set.add(new Person("David", 10));
set.add(new Person("David", 10));
System.out.println(set); // [David:10, abc]
}
}
class Person{
String name;
int age;
Person(String name, int age){
this.name = name;
this.age = age;
}
public boolean equals(Object obj) {
if(obj instanceof Person) {
Person tmp = (Person)obj;
return name.equals(tmp.name) && age == tmp.age;
}
return false;
}
public int hashCode() {
return Objects.hash(name, age); // 객체를 구별하는 기준이 iv 변수
}
public String toString() {
return name + ":" + age;
}
}HashSet클래스의 add()메서드를 통해 새로운 요소를 추가하기 전에 기존에 저장된 요소와 같은 것인지 판별하기 위해 추가하려는 요소의 equals()와 hashCode()를 호출하기 때문에 두 개의 메서드를 목적게 맞게 오버라이팅 해야함
hashCode() 오버라이딩 시 조건 3가지
- 동일한 객체에 대해 hashCode()를 여러 번 호출해도 동일한 값 반환 해야함
- equals()로 비교해서 true를 얻은 두 객체의 hashCode값은 일치해야함
- equals()로 비교한 결과가 fasle인 두 객체의 hashCode() 값이 같을 수도 있다. 하지만 성능 향상을 위해 가능하면hashCode()값이 서로 다른 값을 반환하도록 작성할 것
예제6
import java.util.HashSet;
import java.util.Iterator;
public class prac {
public static void main (String[] args) {
HashSet setA = new HashSet();
HashSet setB = new HashSet();
HashSet setHab = new HashSet();
HashSet setKyo = new HashSet();
HashSet setCha = new HashSet();
setA.add("1"); setA.add("2"); setA.add("3");
setA.add("4"); setA.add("5");
System.out.println("A = " + setA); // A = [1, 2, 3, 4, 5]
setB.add("4"); setB.add("5"); setB.add("6");
setB.add("7"); setB.add("8");
System.out.println("B = " + setB); // B = [4, 5, 6, 7, 8]
Iterator it = setB.iterator();
while(it.hasNext()) {
Object tmp = it.next();
if(setA.contains(tmp))
setKyo.add(tmp);
}
it = setA.iterator();
while(it.hasNext()) {
Object tmp = it.next();
if(!setB.contains(tmp))
setCha.add(tmp);
}
it = setA.iterator();
while(it.hasNext()) {
Object tmp = it.next();
setHab.add(tmp);
}
it = setB.iterator();
while(it.hasNext()) {
Object tmp = it.next();
setHab.add(tmp);
}
System.out.println("A ∩ B = " + setKyo); // A ∩ B = [4, 5]
System.out.println("A ∪ B = " + setHab); // A ∪ B = [1, 2, 3, 4, 5, 6, 7, 8]
System.out.println("A - B = " + setCha); // A - B = [1, 2, 3]
}
}contains() 메서드와 add() 메서드를 통해 교집합, 합집합, 차집합 구현
◎ TreeSet 클래스
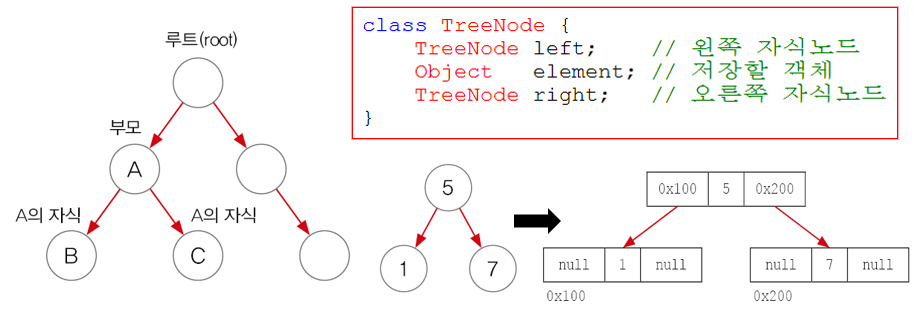
- 이진 검색 트리(binary search tree)라는 자료구조의 형태로 데이터를 저장하는 컬렉션 클래스
- 링크드 리스트(LinkedList)처럼 각 요소(node)가 나무(tree)형태로 연결된 구조
- 이진 트리는 모든 노드가 최대 두개의 하위 노드를 갖음 (부모-자식관계)
- 이진 검색 트리는 부모보다 작은 값을 왼쪽에, 큰 값은 오른쪽에 저장
- HashSet보다 데이터 추가, 삭제에 시간이 더 오래 걸림
- 중복값 저장 x
- 검색(범위검색)이나 정렬 기능 뛰어남
- import java.util.TreeSet; 쓸 것
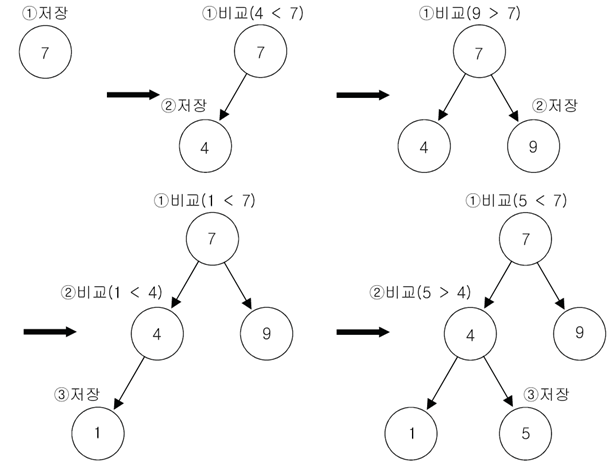
■ 데이터 저장과정
- boolean add(Object o)
- TreeSet에 저장되는 객체가 Comparable 인터페이스를 구현하던가 아니면 TreeSet에게 Comparator 인터페이스를 제공해서 두 객체를 비교할 방법을 알려줘야함. 그렇지 않으면 TreeSet에 객체를 저장할 때 예외 발생
■ TreeSet 클래스 생성자
| 생성자 | 설명 |
| TreeSet() | TreeSet() 객체 생성 |
| TreeSet(Collection c) | 컬렉션(c)을 저장한 TreeSet 객체 생성 |
| TreeSet(Comparator comp) | 주어진 정렬조건(comp)으로 정렬한 TreeSet 객체 생성 |
■ TreeSet 클래스 메서드
| 반환타입 | 메서드 | 설명 |
| boolean | add(Object o) | 요소 추가 |
| boolean | addAll(Collection c) | c에 저장된 요소 추가 |
| Object | ceiling(Object o) | 지정된 객체와 같은 객체 반환 없으면 큰 값을 가진 객체 중 제일 가까운 값 객체 반환 없으면 null |
| Object | lower(Object o) | 지정된 객체보다 작은 값을 가진 객체 중 제일 가까운 값 객체 반환 없으면 null |
| Object | floor(Object o) | 지정된 객체와 같은 객체 반환 없으면 작은 값을 가진 객체 중 제일 가까운 값의 객체 반환 없으면 null |
| Object | higher(Object o) | 지정된 객체보다 큰 값을 가진 객체 중 제일 가까운 값의 객체 반환 없으면 null |
| ① SortedSet<E> ② NavigableSet<E> |
① headSet(Object toElement) ② headSet(Object toElement, boolean inclusive) |
① 지정된 객체보다 작은 값의 객체들 반환 ② 지정된 객체보다 작은 값의 객체들 반환. inclusive가 true면 지정도니 객체값도 포함 |
| ① SortedSet<E> ② NavigableSet<E> |
① tailSet(Object fromElement) ② tailSet(Object fromElement, boolean inclusive) |
① 지정된 객체보다 크거나 같은 값의 객체들을 반환 ② 지정된 객체보다 크거나 같은값 반환. inclusive가 false면 지정된 객체값 포함 안됨 |
| void | clear() | 저장된 모든 객체 삭제 |
| Object | clone() | TreeSet 복제하여 반환 |
| Comparator | comparator() | TreeSet의 정렬 기준(Comparator) 반환 |
| boolean | contains(Object o) | 지정된 객체(o)를 포함되어 있는지 확인. 포함하면 true |
| boolean | containsAll(Collection c) | 컬렉션(c)에 저장된 객체를 모두 포함하는지 확인. 모두 포함하면 true |
| NavigableSet | descendingSet() | TreeSet에 저장된 요소들을 역순으로 정렬해서 반환 |
| Object | first() | 정렬된 순서에서 첫 번째 객체 반환 |
| Object | pollFirst() | TreeSet의 첫 번째 요소 (제일 작은 값) 반환 |
| Object | last() | 정렬된 순서에서 마지막 객체 반환 |
| Object | pollLast() | TreeSet의 마지막 번째 요소(제일 큰 값) 반환 |
| boolean | isEmpty() | 비어있는지 확인. 비어있으면 true |
| Iterator | iterator() | TreeSet → iterator 변환 후 반환 |
| boolean | remove(Object o) | 지정된 객체 삭제 |
| boolean | retainAll(Collection c) | 주어진 컬렉션(c)과 공통된 요소만 남기고 나머지 전부 삭제 교집합 |
| int | size() | 저장된 객체 개수 삭제 |
| Spliterator | spliterator() | TreeSet → Spliterator 변환 후 반환 |
| ① SortedSet<E> ②NavigableSet<E> |
① subSet(Object fromElement, Object toElement) ② subSet(E fromElement, boolean fromInclusive, E toEelement, boolean toInclusive) |
① 범위 검색(fromElement ~ toElement)의 결과를 반환 끝 범위인 toElement 값 포함 안됨 ② 범위 검색(fromElement ~ toElement)의 결과를 반환 fromInclusive가 true면 시작값 포함, toIncluesive가 true면 끝값 포함 |
| Object[] | toArray() toArray(Object[] a) |
지정된 객체를 배열로 반환 지정된 객체를 객체배열(a)에 저장하여 반환 |
예제1
import java.util.Set;
import java.util.TreeSet;
public class prac {
public static void main (String[] args) {
Set set = new TreeSet();
for(int i=0; set.size()<6; i++) {
int num = (int)(Math.random() * 45) +1;
set.add(num);
}
System.out.println(set);
}
}
/* 출력값 (매번 바뀜)
[2, 16, 34, 41, 42, 45]
*/HashSet을 이용한 로또번호 만들기와 같은 TreeSet을 이용한 로또번호 만들기
HashSet으로 로또 번호 만들 때는 정렬을 해줘야했지만 TreeSet은 값을 저장할 때 정렬된 채로 저장하기 때문에 따로 정렬을 안해줘도 됨
예제2
import java.util.TreeSet;
public class prac {
public static void main (String[] args) {
TreeSet set = new TreeSet();
String from = "b";
String to = "d";
set.add("abc"); set.add("alien"); set.add("bat");
set.add("car"); set.add("Car"); set.add("disc");
set.add("dance"); set.add("dZZZZ"); set.add("dzzzz");
set.add("elephant"); set.add("elevator"); set.add("fan");
set.add("flower");
System.out.println(set);
System.out.println("range search : from " + from + " to " + to);
System.out.println("result1 : " + set.subSet(from, to));
System.out.println("result2 : " + set.subSet(from, to + "zzz"));
}
}
/* 출력값
[Car, abc, alien, bat, car, dZZZZ, dance, disc, dzzzz, elephant, elevator, fan, flower]
range search : from b to d
result1 : [bat, car]
result2 : [bat, car, dZZZZ, dance, disc]
*/subSet()을 이용해서 범위검색(range search) 실시
예제3
import java.util.TreeSet;
public class prac {
public static void main (String[] args) {
char ch = ' ';
for(int i=0; i<95; i++) {
System.out.print(ch++);
}
}
}
/* 출력값
!"#$%&'()*+,-./0123456789:;<=>?@ABCDEFGHIJKLMNOPQRSTUVWXYZ[\]^_`abcdefghijklmnopqrstuvwxyz{|}~
*/출력결과 첫 번째 문자는 공백문자. 문자열 오름차순으로 출력한 것
문자열의 경우 정렬 순서는 문자의 코드값이 기준
문자열 오름차순 정렬의 경우 공백, 숫자, 대문자, 소문자 순으로 정렬
예제4
import java.util.TreeSet;
public class prac {
public static void main (String[] args) {
TreeSet set = new TreeSet();
int[] score = {80, 95, 50, 35, 45, 60 ,10 ,100};
for(int i=0; i<score.length; i++)
set.add(new Integer(score[i]));
System.out.println("50보다 작은 값 : " + set.headSet(new Integer(50)));
System.out.println("50보다 큰 값 : " + set.tailSet(new Integer(50)));
}
}
/* 출력값
50보다 작은 값 : [10, 35, 45]
50보다 큰 값 : [50, 60, 80, 95, 100]
*/headSet() 메서드와 tailSet() 메서드를 이용하여 지정된 기준 값 보다 큰 값과 작은 값 얻을 수 있음
◎ Hashtable 클래스
- Hashtable과 HashMap은 Vector와 ArrayList의 관계와 일치 (구버전 - 신버전 관계)
- Hashtable보다 HashMap을 쓸 것
- 동기화 o
◎ HashMap 클래스
- Map 인터페이스를 구현한 대표적인 컬렉션 클래스
- Map 인터페이스 구현 → 키(key)와 값(value)을 묶어서 하나의 데이터(entry)로 저장
- 키(key)와 값(value)을 각각 Object 타입으로 저장
- 동기화 x
- 해싱(hashing)기법으로 데이터 저장
- 데이터 많아도 검색 빠름
- Hashtable은 키(key)나 값(value)으로 null 을 허용하지 않지만, HashMap은 허용
■ HashMap 생성자
| 생성자 | 설명 |
| HashMap() | HashMap 객체 생성 |
| HashMap(int initialCapacity) | 초기 용량을 설정한 HashMap 객체 생성 |
| HashMap(int initialCapacity, float loadFactor) | 초기용량과 load factor를 지정한 HashMap 객체 생성 load factor은 컬렉션 클래스에 저장공간이 가득 차기 전에 미리 용량을 확보하기 위한 것 ex) load factor 값이 '0.8' 일 경우, 저장공간의 80%가 채워졌을 때 용량이 2배로 늘린다는것을 의미. 기본값은 0.75. 즉 75% |
| HashMap(Map m) | 지정된 Map의 모든 요소를 포함하는 HashMap 객체 생성 |
■ HashMap 클래스 메서드
| 반환타입 | 메서드 | 설명 |
| void | clear() | 모든 요소 제거 |
| Object | clone() | HashMap 객체 복사 |
| boolean | containsKey(Object key) | 키(key)가 포함되어 있는지 알려줌. 포함하면 true |
| boolean | containsValue(Object key) | 값(value)이 포함되어 있는지 알려줌. 포함하면 true |
| Set | entrySet() | 키(key)와 값(value)을 엔트리(key-value)형태로 Set에 저장해서 반환 |
| Object | get(Object key) | 키(key)에 해당하는 값(value) 반환. 없으면 null 반환 |
| Object | getOrDefault(Object key, Object defaultValue) | 키(key)에 해당하는 값(value) 반환. 없으면 기본값(defaultValue)반환 |
| boolean | isEmpty() | 비어있는지 확인. 비어있으면 true |
| Set | keySet() | 모든 키(key)를 Set에 저장하여 반환 |
| Collection | values() | 모든 값(value)을 컬렉션 형태로 반환 |
| Object | put(Object key, Object value) | 키(key)와 값(value)을 저장 후 값(value) 반환 |
| void | putAll(Map m) | Map에 저장된 모든 요소 저장 |
| Object | remove(Object key) | 키(key)에 해당하는 값(value) 제거 |
| Object boolean |
replace(Object key, Object value) replace(Object key, Object oldValue, Object newValue) |
키(key)에 해당하는 값 변경 키(key)에 해당하는 값 변경. 성공하면 true |
| int | size() | 저장된 요소 개수 반환 |
예제1
import java.util.HashMap;
import java.util.Scanner;
public class prac {
public static void main (String[] args) {
HashMap map = new HashMap();
map.put("myId", "1234");
map.put("asdf", "1111");
map.put("asdf", "1234");
Scanner s = new Scanner(System.in);
while(true) {
System.out.println("id와 pwd 입력할 것");
System.out.print("id : ");
String id = s.nextLine().trim();
System.out.print("pwd : ");
String pwd = s.nextLine().trim();
System.out.println();
if(!map.containsKey(id)) {
System.out.println("id 없음");
continue;
}
if(!map.get(id).equals(pwd)) {
System.out.println("비밀번호 일치x");
} else {
System.out.println("id와 비밀번호 일치");
break;
}
} // end of While
}
}
예제2
import java.util.Collection;
import java.util.Collections;
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
import java.util.Set;
public class prac {
public static void main (String[] args) {
HashMap map = new HashMap();
map.put("김자바", new Integer(100));
map.put("이자바", new Integer(100));
map.put("강자바", new Integer(80));
map.put("안자바", new Integer(90));
Set set = map.entrySet();
Iterator it = set.iterator();
while(it.hasNext()) {
Map.Entry e= (Map.Entry)it.next();
System.out.println(e.getKey() + ", " + e.getValue());
}
set = map.keySet();
System.out.println("참가자 명단 : " + set);
Collection values = map.values();
it= values.iterator();
int total=0;
while(it.hasNext()) {
total += (int)it.next();
}
System.out.println("총점 : " + total);
System.out.println("평균 : " + total/map.size());
System.out.println("최고 점수 : " + Collections.max(values));
System.out.println("최저 점수 : " + Collections.min(values));
}
}
/* 출력값
안자바, 90
김자바, 100
강자바, 80
이자바, 100
참가자 명단 : [안자바, 김자바, 강자바, 이자바]
총점 : 370
평균 : 92
최고 점수 : 100
최저 점수 : 80
*/
예제3
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
import java.util.Set;
public class prac {
static HashMap phoneBook = new HashMap();
public static void main (String[] args) {
addPhoneNo("친구", "이자바", "010-111-1111");
addPhoneNo("친구", "김자바", "010-222-2222");
addPhoneNo("친구", "김자바", "010-333-3333");
addPhoneNo("회사", "김대리", "010-444-4444");
addPhoneNo("회사", "김대리", "010-555-5555");
addPhoneNo("회사", "박대리", "010-666-6666");
addPhoneNo("회사", "이과장" ,"010-777-7777");
addPhoneNo("세탁", "010-888-8888");
printList();
}
static void addPhoneNo(String groupName, String name, String tel) {
addGroup(groupName);
HashMap group = (HashMap)phoneBook.get(groupName);
group.put(tel, name);
}
static void addPhoneNo(String name, String tel) {
addPhoneNo("기타", name, tel);
}
static void addGroup(String groupName) {
if(!phoneBook.containsKey(groupName)) phoneBook.put(groupName, new HashMap());
}
static void printList() {
Set set = phoneBook.entrySet();
Iterator it = set.iterator();
while(it.hasNext()) {
Map.Entry me = (Map.Entry)it.next();
Set subSet = ((HashMap)me.getValue()).entrySet();
System.out.println("* " + me.getKey() + "[" + subSet.size() +"]");
Iterator subIt = subSet.iterator();
while(subIt.hasNext()) {
Map.Entry subMe = (Map.Entry)subIt.next();
String name = (String)subMe.getValue();
String tel = (String)subMe.getKey();
System.out.println(name + ", " + tel);
}
System.out.println();
}
}
}
/* 출력값
* 기타[1]
세탁, 010-888-8888
* 친구[3]
이자바, 010-111-1111
김자바, 010-222-2222
김자바, 010-333-3333
* 회사[4]
이과장, 010-777-7777
김대리, 010-444-4444
김대리, 010-555-5555
박대리, 010-666-6666
*/HashMap은 키(key)와 값(value)을 모두 Object 타입으로 저장하기 때문에 값(value)을 HashMap 타입으로 저장 가능
예제4
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
public class prac {
public static void main (String[] args) {
String[] data = {"A", "K", "A", "K", "D", "K", "A", "K", "k", "K", "Z", "D"};
HashMap map = new HashMap();
for(int i=0; i<data.length; i++) {
if(map.containsKey(data[i])) {
map.put(data[i], (int)map.get(data[i])+1);
} else {
map.put(data[i], 1);
}
} // end of for
Iterator it = map.entrySet().iterator();
while(it.hasNext()) {
Map.Entry entry = (Map.Entry)it.next();
int value = (int)entry.getValue();
System.out.println(entry.getKey() + " : " + printBar('#', value) + " "+value);
}
}
static String printBar(char ch, int value) {
char[] bar = new char[value];
for(int i=0; i<bar.length; i++) {
bar[i] = ch;
}
return new String(bar);
}
}
/* 출력값
A : ### 3
D : ## 2
Z : # 1
K : ##### 5
k : # 1
*/한정된 범위 내에 있는 순차적인 값들의 빈도수는 배열을 이용하지만, 이처럼 한정되지 않은 범위의 비순차적인 값들의 빈도수는 HashMap을 이용해서 구할 수 있음
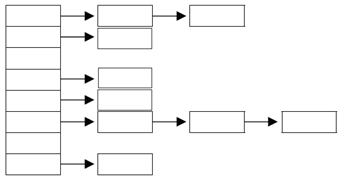
■ 해싱(hashing) 과 해시함수(hash function)
- 해싱이란 해시함수를 이용해서 데이터를 해시테이블(hash table)에 저장하고 검색하는 기법
- 해시함수는 데이터가 저장되어 있는 곳을 알려주기 때문에 원하는 데이터 빠르게 찾을 수 있음
- 해싱을 구현한 컬렉션 클래스는 HashSet, HashMap, Hashtable 등이 있음
- Object클래스에 정의된 hashCode() 메서드를 오버라이딩하여 해시함수로 사용할 것
- Object클래스에 정의된 hashCode()는 객체의 주소를 이용한 알고리즘으로 해시코드를 만들어 내기 때문에 모든 객체에 대해 hasCode()를 호출한 결과가 서로 다름
- hashCode()를 오버라이딩할 때 키값이 서로 일치하는지 비교하는 방식으로 구현할 것
- 해싱에서 사용하는 자료구조는 배열와 링크드 리스트의 조합으로 구성되어 있음
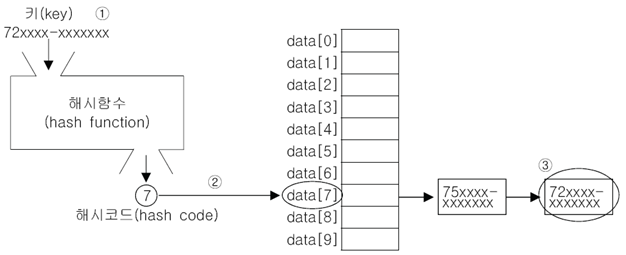
① 검색하고자 하는 값의 키로 해시함수 호출
② 해시함수의 계산결과(해시코드)로 해당 값이 저장되어 있는 링크드 리스트 찾음
③ 링크드 리스트에서 검색한 키와 일치하는 데이터 찾음
※ 해시함수는 같은 키에 대해 항상 같은 해시코드를 반환해야함. 그러나 서로 다른 키일지라도 같은 값의 해시코드를 반환할 수 있음
◎ TreeMap 클래스
- 범위 검색과 정렬에 유용한 컬렉션 클래스
- 검색 성능은 HashMap이 TreeMap보다 더 뛰어남
- 범위 검색이나 정렬이 필요한 경우에는 TreeMap이 HashMap보다 더 뛰어남
- HashMap보다 데이터 추가/삭제 시간이 더 오래 걸림
- 이진검색트리의 형태로 키(key)와 값(value)의 쌍으로 이루어진 데이터를 저장
■ TreeMap 클래스 생성자
| 생성자 | 설명 |
| TreeMap() | TreeMap 객체 생성 |
| TreeMap(Comparator c) | 주어진 기준(c)으로 정렬된 TreeMap 객체 생성 |
| TreeMap(Map m) | 주어진 Map에 저장된 모든 요소를 포함하는 TreeMap 객체 생성 |
| TreeMap(SortedMap m) | 주어진 SortedMap에 저장된 모든 요소를 포함하는 TreeMap 객체 생성 |
■ TreeMap 클래스 메서드
| 반환타입 | 메서드 | 설명 |
| Map.Entry | ceilingEntry(Object key) | 지정된 key와 일치하거나 큰 것 중 제일 작은 것의 키(key)와 값(value)의 쌍(Map.Entry) 반환 없으면 null 반환 |
| Object | ceilingKey(Object key) | 지정된 key와 일치하거나 큰 것 중 제일 작은 것의 키(key) 반환 없으면 null 반환 |
| void | clear() | 모든 요소 제거 |
| Object | clone() | TreeMap 객체 복사 |
| Comparator | comparator() | 정렬기준 반환. 지정되어있지 않으면 null 반환 |
| boolean | containsKey(Object key) | 키(key)가 포함되어있는지 확인. 포함되어있으면 true |
| boolean | containsValue(Object value) | 값(value)가 포함되어있는지 확인. 포함되어있으면 true |
| NavigableSet | descendingKeySet() | 키(key)를 역순으로 정렬해서 NaviableSet에 담아서 반환 |
| Set | entrySet() | 키(key)와 값(value)을 엔트리(key-value)형태로 Set에 저장해서 반환 |
| Map.Entry | firstEntry() | 첫 번째(가장 작은) 키(key)와 값(value)의 쌍(Map.Entry) 반환 |
| Obejct | firstKey() | 첫 번째(가장 작은) 키(key) 반환 |
| Map.Entry | lastEntry() | 마지막(가장 큰) 키와 값(value)의 쌍(Map.Entry) 반환 |
| Object | lastKey() | 마지막(가장 큰) 키(key) 반환 |
| Map.Entry | floorEntry(Object key) | 지정된 key와 일치하거나 작은 것 중에서 제일 큰 키(key)의 쌍(Map.Entry) 반환 없으면 null 반환 |
| Object | floorKey(Object key) | 지정된 key와 일치하거나 작은 것 중에서 제일 큰 키(key) 반환 없으면 null 반환 |
| Object | get(Object key) | key에 해당하는 값(value) 반환 |
| SortedMap NavigableMap |
haedMap(Object toKey) haedMap(Object toKey, boolean inclusive) |
첫 번째 요소부터 toKey 범위까지 속한 모든 요소가 담긴 SortedMap 객체 반환 (toKey는 포함x) 첫 번째 요소부터 toKey 범위까지 속한 모든 요소가 담긴 NavigableMap 객체 반환 (toKey는 포함x) inclusive 값이 true면 toKey값 포함 |
| Map.Entry | higherEntry(Object key) | 지정된 key보다 큰 키 중에서 제일 작은 키의 쌍(Map.Entry) 반환 없으면 null 반환 |
| Object | higherKey(Object key) | 지정된 key보다 큰 키 중에서 제일 작은 키(key) 반환 없으면 null 반환 |
| Map.Entry | lowerEntry(Object key) | 지정된 key보다 작은 키 중에서 제일 큰 키의 쌍(Map.Entry)을 반환 없으면 null |
| Object | lowerKey(Object key) | 지정된 key보다 작은 키 중에서 제일 큰 키 반환 없으면 null |
| boolean | isEmpty() | 비어있는지 확인. 비어있으면 true |
| Set | keySet() | 저장된 모든 키(key) 반환 |
| NavigableSet | navigableKeySet() | 모든 키가(key) 담긴 NaviableSet 반환 |
| Map.Entry | pollFirstEntry() | 첫번째 요소(제일 작은) 키(key) 제거한 후 Map.Entry 반환 |
| Map.Entry | pollLastEntry() | 마지막 요소(제일 큰) 키(key) 제거한 후 Map.Entry 반환 |
| Object | put(Object key, Object value) | 요소 추가 |
| void | putAll(Map map) | Map에 저장된 모든 요소 추가 |
| Object | remove(Object key) | 요소 제거 |
| Object | replace(Object key, Object oldValue, Object newValue) | 기존의 key에 해당하는 값(value)을 새로운 값(newValue)으로 변경 성공하면 true |
| int | size() | 요소 개수 |
| ① SortedMap ② NavigableMap |
① subMap(Object fromKey, boolean fromInclusive, Object toKey, boolean toInclsive) ② subMap(Object fromKey, Object toKey) |
① 지정된 두 개의 키 사이에 포함되어 있는 모든 요소를이 담긴 SortedMap 반환 (toKey 포함 x) ② 지정된 두 개의 키 사이에 포함되어 있는 모든 요소를이 담긴 SortedMap 반환 fromInclusive 가 true면 fromKey 포함, toInclusive가 true면 toKey 포함 |
| ① SortedMap ② NavigableMap |
① tailMap(Object fromKey) ② tailMap(Object fromKey, boolean inclusive) |
① fromKey보다 크거나 같은 값들의 모든 요소들이 담긴 SortedMap 반환 ② fromKey보다 큰 값들의 모든 요소들이 담긴 SortedMap 반환 inclusive가 true면 fromKey 포함 |
| Collection | values() | 모든 값(value)을 컬렉션 형태로 반환 |
예제
import java.util.ArrayList;
import java.util.Collections;
import java.util.Comparator;
import java.util.Iterator;
import java.util.List;
import java.util.Map;
import java.util.Set;
import java.util.TreeMap;
public class prac {
public static void main (String[] args) {
String[] data = {"A", "K", "A", "K", "D", "K", "A", "K", "K", "K", "Z", "D"};
TreeMap map = new TreeMap();
for(int i=0; i<data.length; i++) {
if(map.containsKey(data[i])) {
map.put(data[i], (int)map.get(data[i])+1);
} else {
map.put(data[i], 1);
}
}
Iterator it = map.entrySet().iterator();
System.out.println("== 기본정렬 ==");
while(it.hasNext()) {
Map.Entry entry = (Map.Entry)it.next();
int value = ((Integer)entry.getValue()).intValue();
System.out.println(entry.getKey() + " : " + printBar('#', value) + " " + value);
}
System.out.println();
// map을 ArrayList로 변환한 다음에 Collections.sort()로 정렬
Set set = map.entrySet();
List list = new ArrayList(set);
Collections.sort(list, new ValueComparator());
it = list.iterator();
System.out.println("== 값의 크기가 큰 순서로 정렬 ==");
while(it.hasNext()) {
Map.Entry entry = (Map.Entry)it.next();
int value = ((Integer)entry.getValue()).intValue();
System.out.println(entry.getKey() + " : " + printBar('#', value) + " " + value);
}
}
static String printBar(char ch, int value) {
char[] bar = new char[value];
for(int i=0; i<bar.length; i++) {
bar[i] = ch;
}
return new String(bar);
}
static class ValueComparator implements Comparator{
public int compare(Object o1, Object o2) {
if(o1 instanceof Map.Entry && o2 instanceof Map.Entry) {
Map.Entry e1 = (Map.Entry)o1;
Map.Entry e2 = (Map.Entry)o2;
int v1 = ((Integer)(e1.getValue())).intValue();
int v2 = ((Integer)(e1.getValue())).intValue();
return v2 -v1;
}
return -1;
}
}
}
/* 출력값
== 기본정렬 ==
A : ### 3
D : ## 2
K : ###### 6
Z : # 1
== 값의 크기가 큰 순서로 정렬 ==
A : ### 3
D : ## 2
K : ###### 6
Z : # 1
*/TreeMap을 사용했기에 키(key)가 기본적으로 오름차순으로 정렬되어 있음.
Comparator를 구현한 클래스와 Collections.sort(List list, Comparator c)를 이용해서 값에 대한 내림차순으로 정렬
◎ Properties 클래스
- Hashtable을 상속받아 구현한 것
- Map 특성상 저장순서x , 중복 x
- Hashtable은 키와 값을 (Object, Object)의 형태로 저장하는데 Properties는 (String, String)의 형태로 저장하기에 보다 단순화된 컬렉션 클래스임
- 주로 애플리케이션의 환경 설정과 관련된 속성(property)을 저장하는데 사용되며 데이터를 파일로부터 읽고 쓰는 편리한 기능 제공
- import java.util.Properties; 쓸 것
예제1
import java.util.Enumeration;
import java.util.Properties;
public class prac {
public static void main (String[] args) {
Properties prop = new Properties();
prop.setProperty("timeout", "30");
prop.setProperty("language", "kr");
prop.setProperty("size", "10");
prop.setProperty("capacity", "10");
Enumeration e = prop.propertyNames();
while(e.hasMoreElements()) {
String element = (String)e.nextElement();
System.out.println(element + ", " + prop.getProperty(element) );
}
System.out.println();
prop.setProperty("size", "20");
System.out.println(prop.getProperty("size"));
System.out.println(prop.getProperty("capacity", "20"));
System.out.println(prop.getProperty("Hello", "값 없음"));
System.out.println(prop); // prop에 저장된 요소 출력
System.out.println();
prop.list(System.out); // prop에 저장된 요소들을 화면(System.out)에 출력
}
}
/* 출력값
capacity, 10
size, 10
timeout, 30
language, kr
20
10
값 없음
{capacity=10, size=20, timeout=30, language=kr}
-- listing properties --
capacity=10
size=20
timeout=30
language=kr
*/setProperty() 메서드는 단순히 Hashtable 클래스의 put() 메서드를 호출해서 요소 저장함
예제2
/* input2.txt */
# 메모장 주석주석
name = Seng Namkung
data =9,1,5,2,8,13,26,11,35,1import java.io.FileInputStream;
import java.io.IOException;
import java.util.Properties;
public class prac {
public static void main (String[] args) {
Properties prop = new Properties();
try {
prop.load(new FileInputStream("input2.txt"));
} catch (IOException e) {
System.out.println("지정된 파일 못 찾음");
System.exit(0);
}
String name = prop.getProperty("name");
String[] data = prop.getProperty("data").split(",");
int max=0, min =0, sum = 0;
for(int i=0; i<data.length; i++) {
int intValue = Integer.parseInt(data[i]);
if(i==0) max = min = intValue;
if(max < intValue) max = intValue;
else if(intValue < min) min = intValue;
sum += intValue;
}
System.out.println("이름 : " + name);
System.out.println("최대값 : " + max);
System.out.println("최소값 : " + min);
System.out.println("합계 : " + sum);
System.out.println("평균 : " + (sum*100.0/data.length)/100);
}
}
/* 출력값
이름 : Seng Namkung
최대값 : 35
최소값 : 1
합계 : 111
평균 : 11.1
*/외부파일(input2.txt)로부터 데이터를 입력받아온 예제
외부파일의 형식은 키(key) 와 값(value)이 '=' 로 연결된 형태이어야 함
문장 첫 번 째 문자가 '#' 인 경우 주석으로 처리됨
외부 데이터가 한글일 경우 인코딩문제로 한글이 깨질 수 있기 때문에 아래와 같이 작성할 것
String name = prop.getProperty("name");
try{
name = new String(name.getBytes("8859_1"), "EUC-KR");
} catch(Exception e){}위 코드는 파일로부터 읽어온 데이터의 인코딩을 라틴문자집합(8859_1)에서 한글완성형(EUC-KR 또는 KSC5601)으로 변환해주는 과정을 추가한 것. 우리가 사용하고 있는 OS의 기본 인코딩이 유니코드가 아니라서 이런 변환이 필요함
예제3
/* output.txt */
#Properties Example
#Fri Nov 19 14:12:24 KST 2021
capacity=10
size=10
timeout=30
language=\uD55C\uAE00/* output.xml */
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
-<properties>
<comment>Properties Example</comment>
<entry key="capacity">10</entry>
<entry key="size">10</entry>
<entry key="timeout">30</entry>
<entry key="language">한글</entry>
</properties>import java.io.FileOutputStream;
import java.io.IOException;
import java.util.Properties;
public class prac {
public static void main (String[] args) {
Properties prop = new Properties();
prop.setProperty("timeout", "30");
prop.setProperty("language", "한글");
prop.setProperty("size", "10");
prop.setProperty("capacity", "10");
try {
prop.store(new FileOutputStream("output.txt"), "Properties Example");
prop.storeToXML(new FileOutputStream("output.xml"), "Properties Example");
} catch(IOException e) {
e.printStackTrace();
}
}
}Peroperties에 저장된 데이터를 store() 메서드와 storeXML() 메서드를 이용해서 파일로 저장
output.txt 파일에서는 'language=\uD55C\uAE00' 으로 되어있는데 XML에서는 '<entry key="language">한글</entry>' 로 저장되어 있음. \uD55C\uAE00 유니코드가 한글로 바뀜
XML은 Editplus나 Eclipes에서 한글편집이 가능하므로 데이터에 한글이 포함된 경우 store()보다는 storeToXML()을 이용해서 XML로 저장할 것
예제4
import java.util.Properties;
public class prac {
public static void main (String[] args) {
Properties sysProp = System.getProperties();
System.out.println("java. version : " + sysProp.getProperty("java.version"));
System.out.println("user.language : " + sysProp.getProperty("user.language"));
System.out.println();
sysProp.list(System.out);
}
}
/* 출력값
java. version : 1.8.0_41
user.language : ko
-- listing properties --
java.runtime.name=OpenJDK Runtime Environment
sun.boot.library.path=C:\Users\82107\Desktop\자바의 정석\jdk1.8\...
java.vm.version=25.40-b25
java.vm.vendor=Oracle Corporation
java.vendor.url=http://java.oracle.com/
path.separator=;
java.vm.name=OpenJDK Client VM
file.encoding.pkg=sun.io
user.script=
user.country=KR
sun.java.launcher=SUN_STANDARD
sun.os.patch.level=
java.vm.specification.name=Java Virtual Machine Specification
user.dir=C:\Users\82107\Desktop\자바의 정석\workspa...
java.runtime.version=1.8.0_41-b04
java.awt.graphicsenv=sun.awt.Win32GraphicsEnvironment
java.endorsed.dirs=C:\Users\82107\Desktop\자바의 정석\jdk1.8\...
os.arch=x86
java.io.tmpdir=C:\Users\82107\AppData\Local\Temp\
line.separator=
java.vm.specification.vendor=Oracle Corporation
user.variant=
os.name=Windows 8.1
sun.jnu.encoding=MS949
java.library.path=C:\Users\82107\Desktop\자바의 정석\jdk1.8\...
java.specification.name=Java Platform API Specification
java.class.version=52.0
sun.management.compiler=HotSpot Client Compiler
os.version=6.3
user.home=C:\Users\82107
user.timezone=
java.awt.printerjob=sun.awt.windows.WPrinterJob
file.encoding=MS949
java.specification.version=1.8
user.name=82107
java.class.path=C:\Users\82107\Desktop\자바의 정석\workspa...
java.vm.specification.version=1.8
sun.arch.data.model=32
java.home=C:\Users\82107\Desktop\자바의 정석\jdk1.8\...
sun.java.command=prac
java.specification.vendor=Oracle Corporation
user.language=ko
awt.toolkit=sun.awt.windows.WToolkit
java.vm.info=mixed mode
java.version=1.8.0_41
java.ext.dirs=C:\Users\82107\Desktop\자바의 정석\jdk1.8\...
sun.boot.class.path=C:\Users\82107\Desktop\자바의 정석\jdk1.8\...
java.vendor=Oracle Corporation
file.separator=\
java.vendor.url.bug=http://bugreport.sun.com/bugreport/
sun.cpu.endian=little
sun.io.unicode.encoding=UnicodeLittle
sun.desktop=windows
sun.cpu.isalist=
*/시스템 속성을 가져오는 방법을 보여주는 예제
sysProp.list(Sytem.out) 으로 가져온 값들 중에서 너무 길이서 '...'으로 생략된 값들이 있는데 getProperty()메서드롤 이용하면 생략없이 전체 값을 얻을 수 있음
◎ Collections 클래스
- 컬렉션과 관련된 static 메서드 제공
- import java.util.Collections; 쓸 것
■ 컬렉션 채우기 / 복사/ 정렬 / 검색
- fill(), copy(), sort(), binarySearch()
■ 컬렉션의 동기화 ㅡ synchronizedXXX()
- 멀티 쓰레드(multi-thread) 프로그래밍에서는 하나의 객체를 여러 쓰레드가 동시에 접근할 수 있기 때문에 데이터의 일관성(consistency)을 유지하기 위해서는 공유되는 객체에 동기화(synchronization)이 필요
- ArrayList, HashMap 같은 컬렉션은 동기화 처리가 안되어있으므로 필요시 Collections 클래스의 동기화 메서드를 통해 동기화처리할 것


■ 변경불가(readOnly) 컬렉션 만들기 ㅡ unmodifiableXXX()
- 컬렉션에 저장된 데이터를 보호하기 위해서 컬렉션을 변경할 수 없게, 즉 읽기전용으로 만듦
- 멀티 쓰레드 프로그래밍에서 여러 쓰레드가 하나의 컬렉션을 공유하다보니 데이터가 손상될 수 있으므로 이것을 방지할 때 쓸 것

■ 싱글톤 컬렉션 만들기 ㅡ singletonXXX()
- 단 하나의 객체만을 저장하는 컬렉션을 만들 때 사용

■ 한 종류의 객체만 저장하는 컬렉션 만들기 – checkedXXX()


예제
import java.util.ArrayList;
import java.util.Collections;
import java.util.Enumeration;
import java.util.List;
public class prac {
public static void main (String[] args) {
List list = new ArrayList();
System.out.println(list); // []
Collections.addAll(list , 1,2,3,4,5);
System.out.println(list); // [1, 2, 3, 4, 5]
Collections.rotate(list, 2); // 리스트 배열을 2칸씩 오른쪽으로 옮김
System.out.println(list); // [4, 5, 1, 2, 3]
Collections.swap(list, 0, 2); // 리스트 첫번째 요소와 세번째 요소 교환
System.out.println(list); // [1, 5, 4, 2, 3]
Collections.shuffle(list); // 순서 무작위로 섞음
System.out.println(list); // [2, 4, 3, 5, 1]
Collections.sort(list, Collections.reverseOrder()); // 역순 정렬
System.out.println(list); // [5, 4, 3, 2, 1]
Collections.reverse(list); // 역순 정렬
System.out.println(list); // [1, 2, 3, 4, 5]
Collections.sort(list); // 정렬
System.out.println(list); // [1, 2, 3, 4, 5]
int idx = Collections.binarySearch(list, 3); // 3이 저장된 위치(index) 반환
System.out.println(idx); // 2
System.out.println(Collections.max(list)); // 5
System.out.println(Collections.min(list)); // 1
// 최대값의 반대 정렬 → 최소값
System.out.println(Collections.max(list, Collections.reverseOrder())); //1
Collections.fill(list, 9);
System.out.println(list); // [9, 9, 9, 9, 9]
// list와 크기가 같은 새로운 newList를 생성하고 2로 채움 (단, 결과 변경 불가능)
List newList = Collections.nCopies(list.size(), 2);
System.out.println(newList); // [2, 2, 2, 2, 2]
// 두 리스트의 공통요소가 없으면 true
System.out.println(Collections.disjoint(list, newList)); // true
// newList 요소를 list로 복사
Collections.copy(list, newList);
System.out.println(newList); // [2, 2, 2, 2, 2]
System.out.println(list); // [2, 2, 2, 2, 2]
Collections.replaceAll(list, 2, 1);
Enumeration e = Collections.enumeration(list);
ArrayList list2 = Collections.list(e);
System.out.println(list2); // [1, 1, 1, 1, 1]
}
}
◎ 컬렉션 클래스 정리
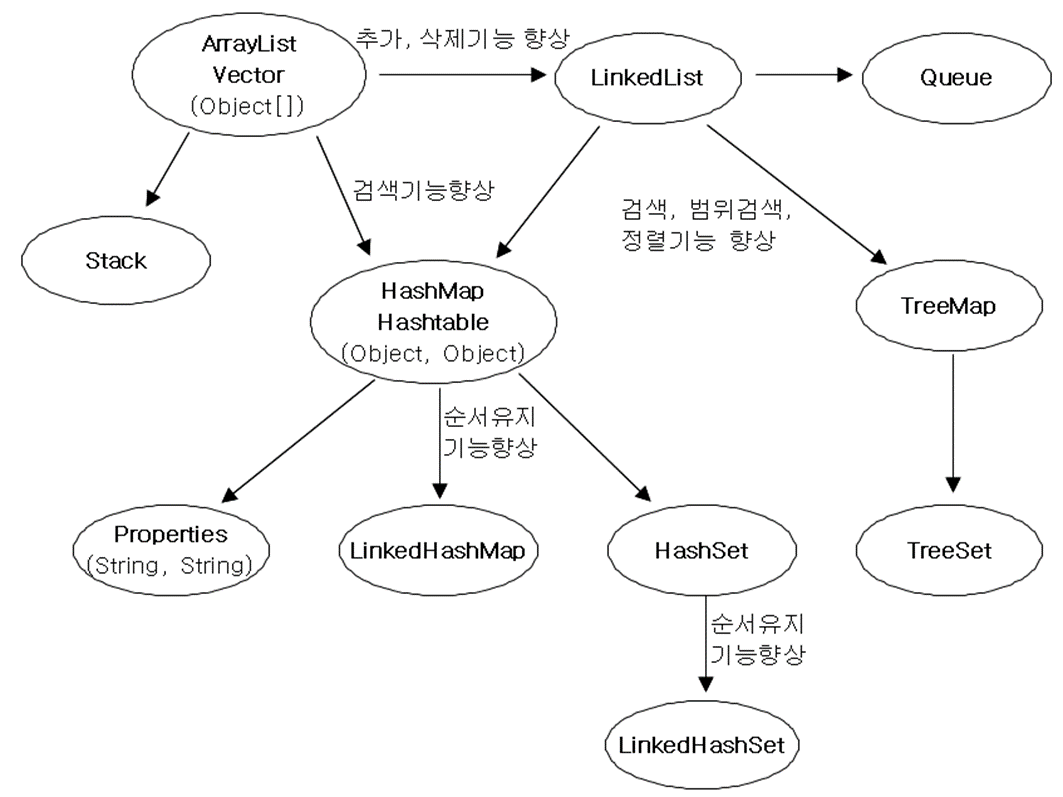
| 컬렉션 | 특징 |
| ArrayList | 배열기반 데이터의 추가/삭제에 불리, 순차적인 추가 삭제는 제일 빠름 임의의 요소에 대한 접근성이 뛰어남 |
| LinkedList | 연결기반 데이터 추가/삭제 유리. 임의의 요소에 대한 접근성이 좋음 |
| HashMap | 배열과 연결이 결합된 형태 데이터 추가/삭제/검색/접근성 모두 뛰어남 검색에는 최고성능 |
| TreeMap | 연결기반 정렬과 검색(특히 범위검색)에 적합 검색 성능은 HashMap보다 떨어짐 |
| Stack | Vector 상속 받아 구현 |
| Queue | LinkedList가 Queue인터페이스 구현 |
| Properties | Hashtable을 상속받아 구현 |
| HashSet | HashMap을 이용해서 구현 |
| TreeSet | TreeMap을 이용해서 구현 |
| LinkedHashMap | HashMap에 저장순서 유지 기능 추가 |
| LinkedHashSet | HashSet에 저장순서 유지 기능 추가 |
'[자바] > 자바의 정석 - 3판' 카테고리의 다른 글
| Chapter 10 날짜와 시간 & 형식화 (0) | 2021.11.08 |
|---|---|
| Chapter 09 java.lang 패키지와 유용한 클래스 (0) | 2021.10.30 |
| Chapter08 예외처리 (0) | 2021.10.27 |
| Chapter07 객체지향2 (0) | 2021.10.17 |
| Chapter06. 객체지향 (0) | 2021.09.25 |