![[DB] 인덱스를 활용한 데이터의 빠른 접근 속도](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FzX7Yu%2FbtrQd8arEBA%2Fk0FrAIkGXHLCiGXPqK1D9k%2Fimg.png)
인덱스를 활용한 빠른 데이터의 접근 속도
📌 인덱스 구조 도입
데이터를 빠르게 접근하기 위해서 인덱스가 필요로 한다. 인덱스를 도입하면 데이터를 전체 조회하지 않고, 빠르게 데이터를 조회할 수 있다.

인덱스와 데이터를 분리하여 효율적인 데이터 검색이 가능하다. 이 방식의 데이터 접근 속도는 데이터의 양과 무관하다. 하지만 ① 번과 ② 번이라는 2번의 데이터 접근이 필요하는 단점이 있다.
인덱스 데이터는 본체의 데이터와 별도로 관리하기 때문에 본체의 데이터를 업데이트할 때, 인덱스 데이터도 같이 업데이트 해야한다. 따라서 업데이트 비용도 증가한다. 대신 데이터 조회 속도가 빠르다.
📌 해시 인덱스
인덱스로 쓰이는 키 값의 데이터는 숫자, 문자열, 날짜/시간 등 여러가지가 될 수 있다. 위 그림에서는 인덱스 파일이 고정 길이로 관리되고 있다. 하지만 다양한 값들이 인덱스로 쓰일 수 있기 때문에 고정 길이로 관리하는 것은 비효율적이다. 왜냐하면 고정으로 관리했을 때, 여유 공간들이 생길 경우 메모리 낭비이기 때문이다.
실제 데이터베이스에서는 키 값을 그대로 관리하지 않는다. 키 값을 해시 함수에 대입하여 해시 값과 값의 쌍을 갖는 구조로 되어있다. 이런 인덱스를 해시 인덱스 라고 한다. 해시 값은 문자열 길이에 상관없이 동일한 크기를 갖는다. 즉, 다양한 값들이 키 값으로 쓰여도 파일 길이가 모두 동일하기에 고정 길이 파일 방식을 사용해도 메모리 낭비가 없다.
해시 계산 비용은 데이터 양에 의존하지 않기 때문에 데이터 양이 늘어도 계싼량은 변경 되지 않는다. 그러므로 처리 계산 량은 O(1) 이다. 가장 빠른 알고리즘이다.
해시 인덱스를 구현할 때, 다른 키 값인데 해시 값이 동일한 경우가 있다. 이런 경우 해시 충돌이라고 한다. 해시 충돌이 생겼을 경우, 다른 데이터를 반환하면 큰일나기 때문에 실제로 내가 조회하려는 데이터가 맞는지에 대한 확인이 필요하다.
그렇다면 해시 인덱스는 만능인가? 아니다. 해시 인덱스로 처리하지 못하는 것들도 존재한다.
- 검색 조건이 범위인 경우. 예) 10,000원 이하의 상품 조회
- 특정 문자열이 포함한 경우. 예) "Final"로 시작하는 문자열 조회
- 데이터 정렬이 필요한 경우. 예) 시간이 최신 순으로 데이터 조회
위 3가지 경우는 해시 인덱스로 처리하지 못한다.
검색 조건이 범위인 경우에는 검색의 키가 '가격'이다. 그 조건은 '10,000원 이하'다. 10,000원도 해당되고, 2,000원도 해당된다. 즉, 키의 값이 몇 개로 반환될지 알 수 없다. 해시 인덱스는 지정한 키 값과 같은 것만 찾을 수 있기 때문에 이런 경우 해시 인덱스를 사용할 수 없다.
특정 문자열이 포함한 경우에는 'Final Fantasy'도 일치하고, 'Final Fight'도 일치한다. 어떤 문자열이 일치할지는 실제로 검색해야 알 수 있다. 검색 패턴을 범위 검색이라고 하는데, 이런 경우에도 해시 인덱스를 사용할 수 없다.
정렬이 필요한 경우에는 일기 포스팅이나 블로그 서비스에서 익숙하다. 그 외에도, 가격이 싼 순서대로 표시하는 경우 등 순서를 따른 결과를 반환해야하는 경우 해시 인덱스는 도움이 되지 않는다.
해시 인덱스는 많은 검색 작업에서 일부 용도만 빠르게 처리할 때 유용하다. 위 3가지 경우는 B+Tree를 사용해야 한다.
📌 B+Tree 인덱스
B+Tree 인덱스는 나무 구조로 된 인덱스다. 정상이 루트 블록, 최하층이 리프 블록이며, 그 사이는 브랜치 블록이 존재한다. 루트 블록과 브랜치 블록은 검색의 키인 사용자 ID에 대해 해당 블록이 어디에 존재하는지에 대한 데이터 위치 정보를 가지고 있다. 최하층의 리프 블록은 실제 데이터의 위치 정보를 가지고 있다.B+Tree 인덱스 검색시 루트 → 브랜치 → 리프 순으로 도달하여 원하는 데이터에 접근할 수 있다.
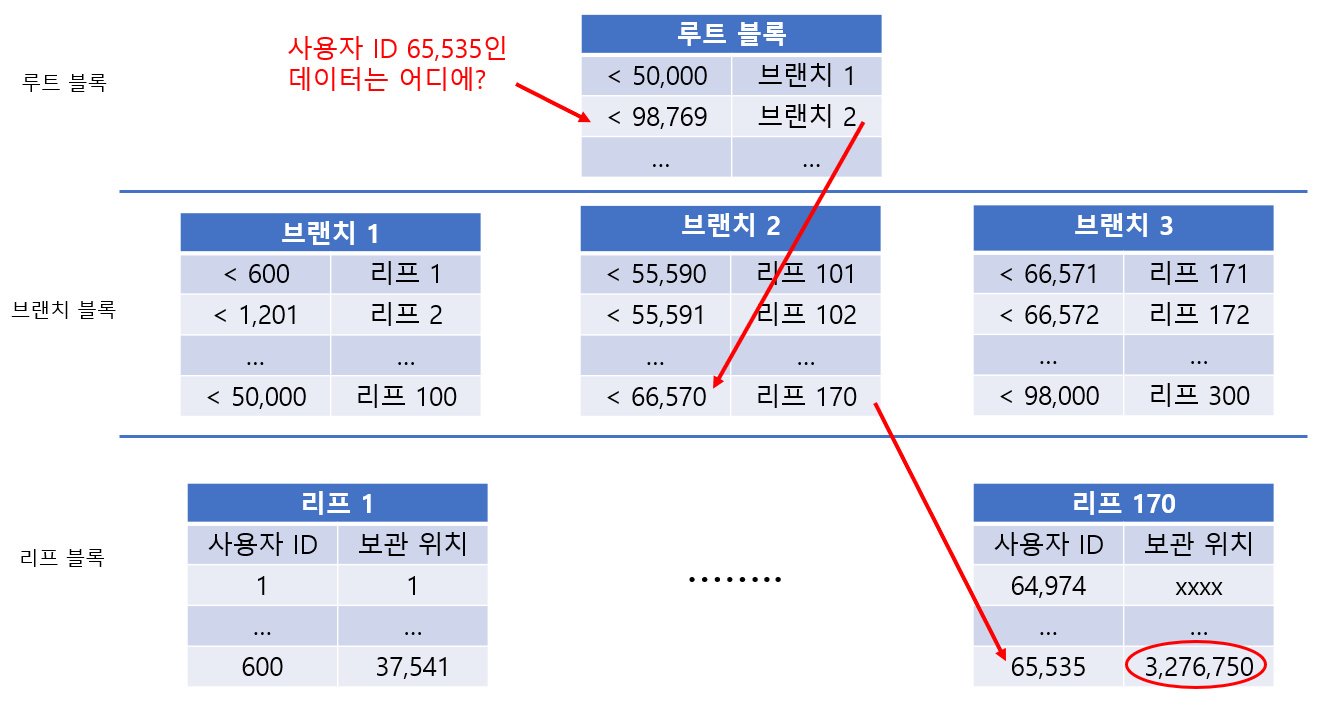
위의 그림을 보면 루트 1회, 브랜치 1회, 리프 1회, 실제 데이터 1회인 총 4회의 데이터 접근이 필요하다. 데이터 접근 횟수가 2회인 해시 인덱스보다 번거롭지만, 해시 인덱스로는 처리하기 힘든 경우에 B+Tree로 유용하게 처리할 수 있다.
레코드 수가 적으면 루트가 브랜치를 겸하면서 루트와 리프밖에 없는 패턴도 존재한다. 레코드 수가 많으면 브랜치 아래에 브랜치가 생기는 4계층 이상 구조가 생긴다. 즉, 레코드 수에 비례하여 계층 수가 생긴다. 계층이 많아질 수록 데이터 접근 횟수가 늘어난다.
B+Tree 인덱스가 이진트리인 경우 N 계층당 2ⁿ개 밖에 기록을 관리할 수 밖에 없다 이진트리인 경우 레코드 N당 탐색에 필요한 계산량이 O(log₂N)이다.
B+Tree 인덱스가 다중트리인 경우시간 시간 복잡도가 로그 밑이 m이며 진수가N이다. 즉, 데이터 접근 횟수를 크게 줄일 수 있다.
💡 B-Tree 인덱스
B-Tree 인덱스 구조는 리프 블록에만 데이터 저장 위치나 추가적인 데이터가 있는 것이 아닌, 브랜치에서도 데이터 저장 위치나 추가적인 데이터를 가질 수 있다. B+Tree 인덱스는 데이터를 조회하기 위해서는 무조건 리프 블록까지 접근해야한다. 하지만 B-Tree는 리프 뿐만 아닌 다른 계층에서도 데이터를 가질 수 있기에 굳이 리프 블록까지 안가도 되므로, 데이터 접근 횟수가 B+Tree보다 적게 일어날 수 있다.
보통 B-Tree 인덱스는 리프 뿐만 아니라 브랜치에서도 키 정보를 가지고 있다. 따라서, 주변의 리프가 아닌 브랜치로 되돌아가 값의 존재 확인을 실시하고, 그 위의 브랜치로 돌아가거나 아니면 다른 리프로 넘어가기 위한 처리가 필요하다.
B+Tree 인덱스는 리프 블록에서 인적한 리프 블록으로 건너가는 것만으로 값의 탐색이 가능하기에 더 효율적이다. 그렇기에 RDBMS의 표준으로 쓰인다.
인덱스 구조 최적화
📌 인덱스를 통한 고유성 보장
데이터를 관리할 때 해당 데이터가 오직 하나만 존재해야하는 경우 등 고유성 보장이 필요한 경우가 있다. 인덱스는 고유성 보장의 목적으로도 사용할 수 있다.
해시 인덱스라면 동일한 ID인 경우 반드시 동일한 해시 값이 된다. B+Tree 인덱스라면 동일한 리프 블록에 도달하기 때문에 적은 비용으로 쉽게 중복 체크를 할 수 있다.
고유성이 보장된 인덱스를 '고유 인덱스', 보장되지 않은 인덱스를 '비고유 인덱스'라고 한다. DB에서는 고유성을 보장하려는 열에 인덱스를 지정하는 것이 필수 조건이다.
📌 멀티 컬럼 인덱스
검색하는데 있어 여러 조건의 인덱스를 '멀티 칼럼 인덱스' 라고 한다. 예를 들어서 '사용자 ID가 100이고, 마지막 수정 날짜가 2009년 9월 30일 이전의 것' 이라는 조건을 지정할 때, 사용자 ID만으로 검색하는 것 보다 사용자 ID와 최종 업데이트 날짜를 모두 검색하는 것이 효과적이다. 대부분 RDMS는 여러 개의 검색 조건을 결합한 인덱스를 만들 수 있으며, AND 조건을 통해 검색 성능을 높일 수 있다.
📌 커버링 인덱스 (실제 데이터 접근 없이 인덱스만 검색)
해시 인덱스와 B+Tree 인덱스를 통해 실제 데이터에 접근한다. 즉, 인덱스를 읽는 단계, 인덱스를 통해 실제 데이터 영역을 읽는 단계인 두 단계의 절차로 이뤄져 있다. 인덱스 부분과 데이터 부분은 서로 독립적인 영역에 존재하기 때문에 양쪽을 한 번의 접근으로 조회할 수 없다. 인덱스와 데이터의 두 번에 걸친 로딩 작업이 필요하다. 하지만 데이터 영역의 접근이 필요 없는 경우도 있다.
커버링 인덱스는 실제 데이터 접근 없이 인덱스로만 해결하는 것이다.검색 패턴에 따라 인덱스를 읽는 것만으로 처리가 완료되는 경우가 있다. 예를 들어서, '가격이 10,000원인 상품의 개수'를 알고 싶을 때, 가격 인덱스에서 '가격 <= 10,000원'의 조건에 맞는 B+Tree 인덱스의 리프 블록 개수만 구하면 된다.. 즉, 데이터 영역에 접근할 필요가 없다.
📌 인덱스 병합
인덱스 병합은 여러 범위 스캔으로 행을 검색하고 결과를 하나로 병합하는 것이다. 여러 개의 인덱스를 동시에 사용하여 각각의 데이터를 처리한 후 하나로 합친다. 예를 들어서 '부서 코드가 100번 또는 입사 연도가 2010년인 직원'을 조회하고 싶을 때, 부서 코드가 100번인 경우와 입사 연도가 2010년인 경우를 각각의 행 번호를 추출한다. 그리고 AND 조건과 OR 조건 등으로 집합 연산을 수행한 후 처리 결과에 해당하는 행 번호에 대해 데이터 영역에 접근한다.
인덱스 영역과 데이터 영역의 업데이트 비용 절감의 노력
📌디스크에 모아서 기록하기
DB 성능에 있어서 랜덤 액세스를 얼마나 적게 일으키냐가 핵심이다. .DB는 랜덤 액세스를 줄이기 위해서, 업데이트된 정보를 메모리나 전용 파일 등에 일시적으로 기록하여 나중에 한꺼번에 리프 블록을 갱신한다. 대표적인것이 MySQL이다. MySQL은 랜덤 라이트보다 훨씬 빠른 시퀀셜 라이트로 빠르게 처리한다.
📌 병렬 갱신으로 성능 높이기
B+Tree 인덱스에 값을 추가/갱신/삭제가 일어날 경우, 인덱스의 리프 블록이 이동시킬 필요가 있다. 이런 처리를 '리프 분할'이라고 한다. 대량의 데이터의 업데이트를 통해 리프 분할이 여기저기서 일어난 경우, 인덱스의 재편성 처리가 완료될 때 까지 참조/갱신 처리를 차단할 경우 멀티 코어 CPU 환경에서는 비효율적이다. 그럴 때 파티션 테이블을 통해 동시성을 높일 수 있다.
파티션 테이블을 통해 데이터들을 병렬 갱신을 할 수 있다. 파티션 테이블이란, 사용자에게는 테이블이 한 개로 보이지만 내부적으로는 여러 개의 테이블로 분할 관리하는 것이다. 인덱스도 여러 개로 구분하고 있기 때문에 병렬 갱신이 가능하다. 또는 락 프리(Lock Free)로 갱신 가능한 알고리즘도 존재한다.
🔍 랜덤 엑세스 횟수를 줄여야 한다.
랜덤 액세스는 DB 성능과 직결된다. DB는 무정지성을 확보하기 위해서 갱신한 데이터를 디스크에 써(write)야한다. 그리고 메모리에 올라와 있지 않은 데이터를 조회할 경우 디스크로부터의 로드가 발생한다. 이렇게 HDD에 접근하는 것이 랜덤 액세스다.
🔍 인덱스를 이용하는 것이 항상 좋은가?
인덱스를 이용하는 것이 항상 좋은 것은 아니다. 인덱스를 업데이트를 하기 위해서 비용이 든다. 업데이트 속도 저하는 데이터의 양이 서서히 증가해 가는 타입의 애플리케이션에서 심각해지기 쉽기 때문에 인덱스를 함부로 부여하는 것이 아니라, 필요한 것만 균형있게 부여해야 한다. 어떤 항목이 인덱스에 적합하고, 어떤 항목이 적합하지 않는지 잘 판단하기 위해서는 사전 설계가 중요하다.
'[DB] > DB' 카테고리의 다른 글
| [DB] 테이블 설계 및 데이터 모델링 (0) | 2022.11.03 |
|---|---|
| [DB] DB의 필요성 (0) | 2022.11.02 |
| [DB] 스프링 부트의 다양한 DB 연동 방법 (0) | 2022.03.31 |